python绘制数学图形(堪比matlab)
在开始之前,我要对latex做一点补充。
上一篇文章中提到了latex绘制流程图,文中给出了一个实例,在具体的应用上也很简单。下面两个网页可能会比较有用,特别是在流程图的绘制上(各类shapes汇总):
http://www.texample.net/tikz/examples/feature/nodes-and-shapes/
流程图判断——菱形,其变扁的方法:
http://bbs.ctex.org/forum.php?mod=viewthread&tid=57980
下面开始今天要说到的主题。matlab固然很牛叉,但是在理解和实现上还是相对复杂的,python利用现有的库,基本可以实现matlab所有的功能,甚至超越之。与前面的文章相对应,python绘图应该主要着眼的是一些比较严谨的数学公式的绘制问题,相对于latex,其图形更加有数学之美。
今天晚上,我又整了一下python的绘图,感觉还是比较方便的,50行不到的代码即可实现比较完美的图形,特别推荐。下面对应的依次是图形和代码:
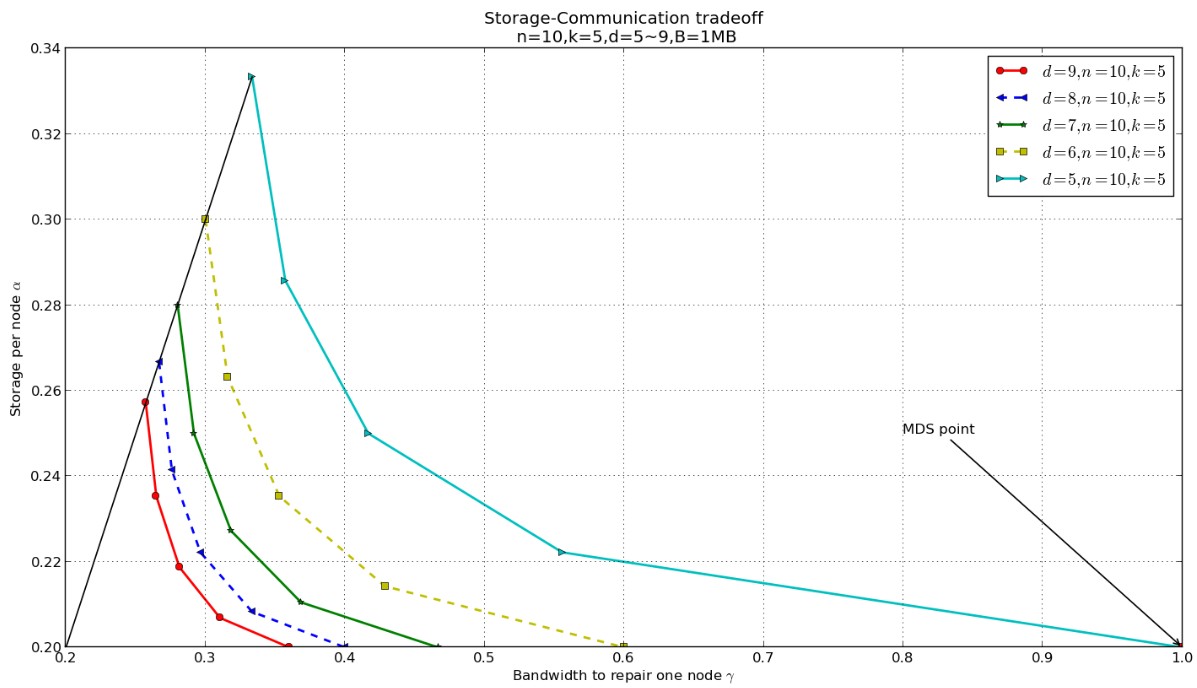
对应的代码很简单:
#!/usr/bin/python
#coding = utf8
import sys
import string
import numpy as np
import matplotlib.pyplot as plt
def f_fun(d, k, i):
a = (2.0*d)/((2.0*k-i-1.0)*i+2.0*k*(d-k+1.0))
return a
def g_fun(d, k, i):
a = (2.0*d-2.0*k+i+1.0)*i*1.0/(2.0*d)
return a
def main():
form = ['ro-', 'b--<', 'g-*', 'y--s', 'c->']
k = 5
d = [9, 8, 7, 6, 5]
x = y = [1.0/k]
for t in range(5):
r = [f_fun(d[t], k, i) for i in range(k-1, -1, -1)]
a = [((1.0-g_fun(d[t], k, i)*r[k-i-1])*1.0/(k-i)) for i in range(k-1, 0, -1)]
a.append(1.0/k)
x.append(r[0])
y.append(a[0])
plt.plot(r, a, form[t], linewidth = 2.0, label = "$d="+str(d[t])+",n=10,k=5$")
plt.plot(x, y, linewidth = 1.2, color = 'black')
plt.plot([1.0], [1.0/k], 'rs')
plt.annotate("MDS point", xy=(1.0, 1.0/k), xycoords = 'data', xytext=(0.8, 0.25), arrowprops=dict(arrowstyle="->", linewidth = 1.2))
#plt.plot([1.0], [1.0/k], 'rs')
plt.legend(loc='upper right')
plt.title("Storage-Communication tradeoff \n n=10,k=5,d=5~9,B=1MB")
plt.ylabel("Storage per node $\\alpha$")
plt.xlabel("Bandwidth to repair one node $\\gamma$")
plt.grid(True)
plt.show()
if __name__ == '__main__':
main()
doxygen系列问题
Doxygen是一个比较强大的、针对源代码的开源文档生成系统,其适用的语言有C++、C、Java、Objective-C、Pyhon、IDL、Fortan、VHDL、PHP、C#以及D语言。现有很多开源项目都使用到了doxygen。它的出现使得文档的维护工作大大简化,只需要根据一定的规则的注释,就可以生成质量比较搞的文档。现在的doygen能支持一般的操作系统,如windows、unix、Mac等等。
下面对doxygen作进一步的分析:
一、安装
由于我使用的是linux系统,所以,整个文章的内容都是关于doxygen在linxu下的使用;在linux下,doxygen的安装如下:
sudo apt-get install doxygen
真正在使用上windows下的doxygen还是比较直观的,应该更适合一些人群,因为有GUI界面供使用,网上的教程也很多。
二、基本使用:
1. 生成配置文件:(filename是相应的配置文件名,如果缺省,默认是Doxyfile):
doxygen -g filename
2.修改配置文件:
这里说一些我认为比较重要的几处,其他的可以根据相应的选择进行设置(其实在配置文档的注释中,各项已经非常明朗了)。
| PROJECT_NAME | 写入你的项目名称,在生成的时候会涉及到 | 默认为"my project" |
| PROJECT_NUMBER | 指的是你工程的版本号 | 可以选择不写 |
| OUTPUT_DIRECTORY | 最后输出的目录选择,例如"./doc/" | 如果不写,默认是当前目录 |
| JAVADOC_AUTOBRIEF | 修改成YES,表示支持java的注释格式 | 默认是NO,在代码中,总要设置几个注释规范 |
| MULTILINE_CPP_IS_BRIEF | 和上面一样,改成YES | 默认是NO,目的和上面一样 |
| INPUT | 源project的目录或者文件名,例如"./lib/" | 可以不写,表示当前的目录 |
| FILE_PATTERNS | 选择如.c/.h/.cpp等的文件 | 没有被选择的,如.py会被过滤掉,即最后不会翻译.py的文件 |
| RECURSIVE | 递归遍历当前目录的子目录,寻找被文档化的程序源文件 | 默认是 NO,修改成 YES |
| HAVE_DOT | 改写成YES | 生成类图等,前提是需要安装了这个组件 |
其他的,个人觉得不太重要,至于其他的可以参看注释,生成文件的每项注释已经非常清楚了。
3. 写注释
这一块不想说太多了,因为已经有很多人都做了讨论,对自己选好的几种注释方式,进行研究一下即可。(可以参考http://www.cnblogs.com/wishma/archive/2008/07/24/1250339.html)
需要说明一点的是,我们在写注释的时候,也要注意使用关键字,我目前为止使用到了@file (为整个文件生成对应的页面,如 .h 文件,则可以生成与 .h 文件对应包含所有函数的整体性文件)、@fn (声明函数,可以还有 @par, @return等等其他描述函数的参数)、@brief (简要描述)等等。在生成的时候注释中的换行往往会被忽略掉,可以使用\n来产生空行。
4. 运行:
doxygen filename(配置文件名)
三、链接网站:
- doxygen的官方网站:http://www.doxygen.nl/index.html
- doxygen手册的翻译网站:http://cpp.ezbty.org/book
现在国内doxygen的使用应该是呈现了逐渐增多的态势,所以关于doxygen方面的博客等有很多很多,虽然大致相同,但是总会有些亮点。具体可以google一下。下面是我现在在学习中的一些问题和心得:
doxygen -g filename
上面是doxygen初始配置文件的生成命令,其实你可以试一下,无论你在哪个目录下,或者以哪个文件名命名这个初始的配置文件,最后得到的文件内容都是一样的,不会因为你放在哪个目录下或文件名不同而内容有所不同。这也就说明了一个问题,在使用doxygen时,对配置文件所处的位置是没有限制的,而关键的问题是对配置文件进行的修改以及设置(input和output path可以对目标文件以及输出的目录进行设置)。
如果在上面命令中缺省filename,最后得到的默认文件Docxyfile,其内容和其他生成的文件内容也是一样的。
在使用的过程中,因为我的粗心,也出现了一个问题。这里指出来,提醒我自己。
配置文件中有“INPUT PATTERNS =”这个设置项,主要作用是如果你之前INPUT了一个目录而不是一个文件的情况下,过滤性的对源码生成文档。例如:
INPUT PATTERNS = *.cc *.h *.cpp
上面表示的就是只针对目录下所有的.cc、.h和.cpp源文件生成文档,其他后缀的文件都会被忽略,而我最开始接触这个东西的时候,在网上搜到的大部分设置都是这样的:
INPUT PATTERNS = *.cc \
*.h \
*.cpp
我知道“\”是一个换行符号,但是我在使用的时候没有注意到“*.cc”和其之间要有空格,所以这样一来始终都生成不了对应的文档。问题的本质应该在于,doxygen在运行的时候,是根据空格来区分多个参数的,如果不加空格,可能直接被识为了后缀为.cc*.h*.cpp的文件,而目录下是没有这样的文件的,所以会出错。
latex与流程图 (pgf&tizk)
一直觉得在ubuntu下流程图的画法比较伤脑筋,昨天晚上耍了耍latex中的pgf和tizk包,感觉非常不错!值得推荐。
虽然这个包可以绘制出一些数学的图形,但是我不建议,对于数学方面的图形还是用python提供的库比较好一些。该库提供的语法很简单,但是内容却不少,不过还是比较好掌握的。下面给出我尝试绘制属于我自己的纠删码的图。
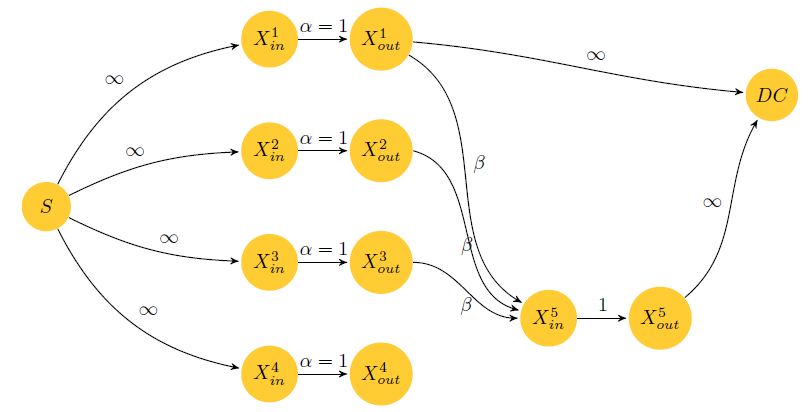
上面这个图的具体代码实现不超过100行,下面你会看到,不过老实说,颜色的配置还是花费了我比较多的时间的,因为latex只提供了6种基本的原色,所以其他颜色只有自己定义了,而且这里曲线的实现不是一个坐标坐标的移动,而是一句话就可以搞定的。多的话就不说了,个人觉得比较简单,具体代码可以看看如下:
\documentclass{article}
\usepackage{pgf}
\usepackage{tikz}
\usetikzlibrary{arrows, decorations.pathmorphing, backgrounds, positioning, fit, petri, automata}
\definecolor{yellow1}{rgb}{1,0.8,0.2}
%opening
\begin{document}
\begin{tikzpicture}[->,>=stealth',shorten >=1pt,auto,node distance=2.8cm,
semithick]
\tikzstyle{every state}=[fill=yellow1,draw=none,text=black]
\node[state] (S) at (-6, 0) {$S$};
\node[state] (xin1) at (-2, 3) {$X^1_{in}$};
\node[state] (xin2) at (-2, 1) {$X^2_{in}$};
\node[state] (xin3) at (-2, -1) {$X^3_{in}$};
\node[state] (xin4) at (-2, -3) {$X^4_{in}$};
\node[state] (xout1) at (0, 3) {$X^1_{out}$};
\node[state] (xout2) at (0, 1) {$X^2_{out}$};
\node[state] (xout3) at (0, -1) {$X^3_{out}$};
\node[state] (xout4) at (0, -3) {$X^4_{out}$};
\node[state] (xin5) at (3, -2) {$X^5_{in}$};
\node[state] (xout5) at (5, -2) {$X^5_{out}$};
\node[state] (DC) at (7, 2) {$DC$};
\path (S) edge[bend left=26] node {$\infty$} (xin1)
edge[bend left=12] node {$\infty$} (xin2)
edge[bend right=12] node {$\infty$} (xin3)
edge[bend right=26] node {$\infty$} (xin4)
(xin1) edge node {$\alpha=1$} (xout1)
(xin2) edge node {$\alpha=1$} (xout2)
(xin3) edge node {$\alpha=1$} (xout3)
(xin4) edge node {$\alpha=1$} (xout4)
(xin5) edge node {$1$} (xout5);
\draw[->] (xout1) to[out=-30,in=150] node {$\beta$} (xin5);
\draw[->] (xout2.east) to[out=-15,in=165] node [below] {$\beta$} (xin5);
\draw[->] (xout3.east) to[out=0,in=180] node [below] {$\beta$} (xin5.west);
\draw[->] (xout1) to[out=-5,in=175] node {$\infty$} (DC);
\draw[->] (xout5) to[out=40, in=-120] node {$\infty$} (DC);
\end{tikzpicture}
\end{document}
接下来这个图(纠删码毁坏一个节点的图)的绘制过程,是在上个图形的基础之上实现的,具体给出加入的代码(整体的实现算是比较明朗):
\draw[line width=2.5pt,red,-] (-1.7,-2.8)--(-0.3,-3.2); \draw[line width=2.5pt,red,-] (-1.7,-3.2)--(-0.3,-2.8); \draw[line width=2.5pt,red,dash pattern=on 6pt off 4pt on 2pt off 4pt,-] (-1,3.8)--(-1,2.5); \draw[line width=2.5pt,red,dash pattern=on 6pt off 4pt on 2pt off 4pt,-] (-1,2.5) to[out=-10,in=170] (1.2,1.2); \draw[line width=2.5pt,red,dash pattern=on 6pt off 4pt on 2pt off 4pt,-] (1.2,1.2) to[out=-100,in=80] (0.8,-1.9);
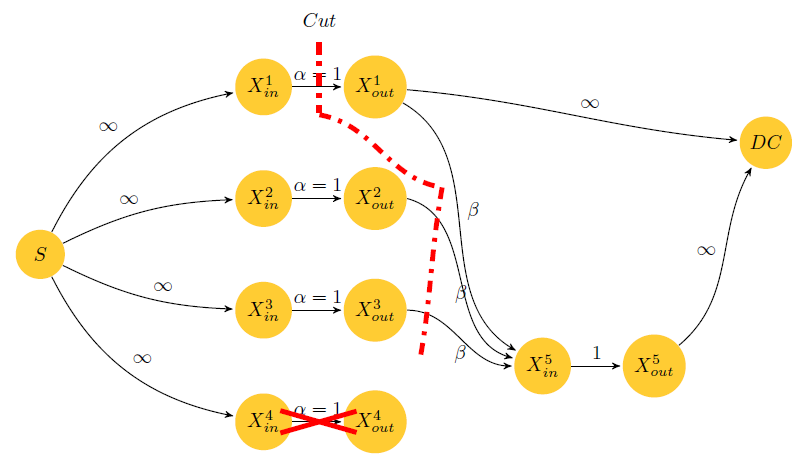
对于资料,我觉得看中文或者博客,还不如看原版的manualpgf,google之即可得到。
my first beamer ppt
继完成自己翻译论文排版之后,我第一次用latex beamer完成了自己的ppt,算是比较不错吧。由于时间仓促,所以在内容上不算是非常充足!
在这次的实现中,我主要的感想有几点:
- 一些错误类型,只有自己见得多了,就知道了,特别是一些特殊符号,很容易就报错了;
- 好的东西是调出来的,最开始的时候或许排版啥的很不好,但是慢点调,总会有属于自己的模版;
- 语言和语言之间很相似,现在站在一个大的整体上看,感觉就是class的声明,接着就是头文件,也就是包,最后就是正文,和其他语言,如C等,都是如出一辙,所以不用害怕,其实也不难。
要说的只有这些吧。当自己遇到困难的时候,千万别恼怒,要知道,这是你在进步的预兆。可以看看我最后生成的最终版:http://wenku.baidu.com/view/1d70280bb52acfc789ebc9c6.html?st=1。
想了想还是附上自己的代码共享给大家,需要注意,目录需要编译两次才出来。我直接用的是latexpdf **.tex:(图片没有给出,大家可以随便弄两张看看)
\documentclass[cjk,slidestop,mathserif]{beamer}
\usepackage{CJK}
\usepackage{beamerthemesplit}
\usepackage{graphicx}
\useoutertheme{infolines}
\usetheme{Warsaw}
\usecolortheme{crane}
\usecolortheme{seagull}
\setbeamertemplate{items}[ball]
\setbeamertemplate{blocks}[rounded][shadow=true]
\setbeamertemplate{navigation symbols}{}%去除底部比较酷的工具条,因为实际应用的很少
\begin{document}
\begin{CJK}{UTF8}{gkai}
\title{博弈论之公平组合游戏}
\author{欧阳梦云}
\institute[HUST]{华中科技大学}
%\date{\today}
\frame{\titlepage}
\frame{\tableofcontents}
\section{Introduction}
\subsection{An example}
\begin{frame}
\vspace{12pt}
\frametitle{An example}\pause
\begin{example}
Description:\\
有21枚石子组成的石堆,两人轮流进行游戏。每次游戏者可以
取走石堆中不超过3枚的石子。谁取走最后一颗为胜利。
\end{example}
\pause
$\clubsuit$ 你会先取么? \\
\vspace{36pt}
\pause
Analysis:1,2,3 || 4 || 5,6,7|| 8 ... \\
\vspace{18pt}
\pause
Conclude:先走,取一个石子
\end{frame}
\subsection{Background}
\begin{frame}
\frametitle{应用背景}
\vspace{12pt}
博弈论在当今的生活中,几乎每个领域都会或多或少的涉及。
\begin{itemize}
\item<1-> 经济学领域中的,一个比较经典的博弈问题就是{\alert{“囚徒困境”}};
\item<2-> 我们熟知的象棋比赛,电脑游戏;
\item<3-> 甚至在生物领域,还存在着动物之间的博弈等等。
\end{itemize}
\vspace{10pt}
\begin{table}
\begin{tabular}{|c|c|c|}
\hline
甲乙策略 & 甲沉默 & 甲背叛 \\
\hline
乙沉默 & 二人同服刑一年 & 乙服刑10年,甲释放 \\
\hline
乙背叛 & 甲服刑10年,乙释放 & 二人同服刑8年 \\
\hline
\end {tabular}
\end {table}
\end{frame}
\subsection{Definition}
\begin{frame}
\frametitle{公平组合游戏}
\vspace{16pt}
公平组合游戏是博弈论的一个子集,它的成立需要如下前提:
%\pause
\vspace{6pt}
\begin{enumerate}
\item<1-> 两个参与者,游戏局面的状态集合是有限的;
\item<2-> 在同一个局面下,两操作者可选择的操作集合完全相同,但每步必须得走;
\item<3-> 无论如何游戏会在有限步内结束,且没有平局;
\item<4-> 当无法进行操作时游戏结束,此时不能进行操作的一方输。
\end{enumerate}
\end{frame}
\begin{frame}[label=here]
\vspace{12pt}
\frametitle{P-position and N-position 定义}
\begin{definition}
P-position:后手必胜局面,winning for the Previous player。 \
\
\vspace{8pt}
N-position:先手必胜局面,winning for the Next player。
\end{definition}
\vspace{24pt}
\pause
上面的例子中已经清晰的给出了这两种状态,\\
\vspace{6pt}
P-position就是上面的0,4,8,12... \\
\vspace{6pt}
N-position就是例如1,2,3,5...
\end{frame}
\subsection{Algorithm}
\begin{frame}
\vspace{12pt}
通过上面的例子我们可以归纳出一般解决公平组合游戏的算法:
\begin{enumerate}
\item <1->将最终状态标记为P-position;
\item <2->通过一步可以到达P-position的,都标记为N-position;
\item <3->找到这样一个position,其所有的选择都只会到达N-position,将其标记为P-position;
\item <4->如果在第3步中找到了一个P-position,则停止。否则继续第二步。
\end{enumerate}
\pause
\pause
\pause
\pause
\hyperlink{here}{\beamerbutton{$\blacklozenge$实例}}
我们需要注意,这个算法是从最后状态分析。\\
\pause
\vspace{12pt}
从算法中,我们也可以看出,P-position和N-position性质: \\
$\clubsuit$ \color{blue}{所有的最终状态都是P-position;} \\
\vspace{6pt}
\pause
$\clubsuit$ \color{blue}{从每个N-position,至少有一种方法可以到P-position;} \\
\vspace{6pt}
\pause
$\clubsuit$ \color{blue}{每个P-position,每种方法都到达N-position。} \\
\end{frame}
\section{nim游戏} %section
\subsection{An Typical Example}
\begin{frame}
\frametitle{An Example}
\vspace{12pt}
\begin{example}
Description: \\
现有5堆石子,石子的个数分别是2,3,4,甲乙两个参与者每次从这3堆石子中任选一堆取走石子,\
每次取走至少一个,至多整堆。最后取光者胜利。
\end{example}
\vspace{16pt}
\pause
\ 问题:利用上面的策略分析依稀,如果你是甲,你会先走么?你该怎么走?
\pause
\pause
Analysis: \\
P-position (0,0,0),如果只有两堆且等量,(0,1,1) or (0,2,2)... \\
\pause
\vspace{12pt}
如果堆的个数增加到100个以上,我们又怎么分析呢?
\end{frame}
\subsection{Conclude}
\begin{frame}
\frametitle{Conclude}
\vspace{12pt}
\begin{alertblock}{Conclude}
其实整个问题比较复杂,不过这类问题已经形成了一个有公式的解法,那就是每堆的个数相互“抑或”,\
例如每堆的个数是$a_{1}$,$a_{2}$,...$a_{n-1}$,$a_{n}$,则 \
$a_{1}$ $\bigoplus$ $a_{2}$ $\bigoplus$ $a_{3}$ ... $a_{n-1}$ $\bigoplus$ $a_{n} $),\
如果最后的结果是0,代表当前状态为P-position; \\
非0,代表当前状态为N-position。\\
\end{alertblock}
\vspace{6pt}
这样一来,问题也很简单了。
\pause
\vspace{20pt}
PS:已经有人给出了准确的证明!大家有兴趣的可以看看。
\end{frame}
\section{Sum of Combinatorial Games}
\subsection{mex definition}
\begin{frame}
\frametitle{mex(minimal excludant)运算}
\vspace{18pt}
\begin{definition}
mex mex运算,就是施加在一个集合上的运算,表示最小的不属于这个集合的非负整数。
\end{definition}
\vspace{8pt}
例如mex$\{$0,1,2,4$\}$=3,mex$\{$2,3,5$\}$=0。
\vspace{12pt}
\pause
\begin{alertblock}{引申}
对于有向无环图,定义关于图的每个顶点的Sprague-Garundy函数g为:g($x$)=mex$\{$g($y$) $\mid$ $y$是$x$的后继$\}$。
\end{alertblock}
\end{frame}
\subsection{The Sprague Grundy Theorem}
\begin{frame}
\frametitle{SG函数和公平组合游戏}
\vspace{14pt}
$\bigstar$上面已经给出了SG函数的定义。现在大家应该有很多疑问,为什么会引出SG函数?? \\
\pause
\vspace{10pt}
$\circlearrowleft$其实我们可以将所有的公平组合游戏抽象成一个有起始点的有向五环图,在顶点上有一枚石子,两名选手交替将石子移动,最后无法移动者为败。
\\
\pause
\vspace{8pt}
$\circlearrowright$这样一来,公平组合游戏中每个局面可以看作图的顶点,而顶点之间的边,即为操作。\
经过抽象之后,很多问题就可以得到解决了,甚至可以给出所有的必胜操作步骤,以及每一步具体怎么操作。
\end{frame}
\begin{frame}
\frametitle{SG函数和公平组合游戏}
\vspace{14pt}
首先,所有最终节点,也就是没有出边的顶点,SG值为0,因为后继集合是空集。\\
\pause
\vspace{6pt}
其次,对于一个$g(x)=0$的顶点$x$,他的后继$y$都满足$g(y)!=0$。\\
\vspace{4pt}
而对于一个$g(x)!=0$的顶点,必定存在一个后继$y$,满足$g(y)=0$。\\
\vspace{10pt}
\pause
\begin{alertblock}{对应到公平组合游戏上}
结合上面所说道的P-position和N-position的定义以及性质,我们可以看到,顶点$x$所代表的position是P-position \
当且仅当$g(x)=0$,我们通过计算有向无环图每个顶点的SG值,就可以找到所有的必胜策略了。
\end{alertblock}
\end{frame}
\begin{frame}
\frametitle{An example}
下图给出的是一个SG推倒函数,其中最开始有4个终节点,SG值都为0,接着a点和b点都被给出,上面的是通过推断的。
\begin{figure}
\includegraphics[width = 8cm]{sg.jpg}
\end{figure}
\end{frame}
\begin{frame}
\frametitle{Conclude}
\vspace{10pt}
\begin{alertblock}{example}
再给出一种情况,有n堆石子,每次可以从第一堆里去1,2,3颗,可以从第二堆里取奇数颗,第三堆及以后可以取任意颗。
\end{alertblock}
\vspace{6pt}
这个问题我们又怎么解决呢?? \\
\pause
\vspace{10pt}
其实我们可以把这个问题看作3个游戏,每个游戏对应有向无环图的一个顶点,这样一来,有向无环图有3个顶点。 \\
\vspace{4pt}
\pause
也就是进一步将SG函数抽象,\\
\pause
对应的第一个游戏,SG值是$x\%2$($x$是一堆石子的个数);\\
\pause
第二个游戏的SG值是$x\%2$; \\
\pause
第三个游戏对应的是一个$n-2$的nim游戏。
\end{frame}
\begin{frame}
\frametitle{Conclude}
\vspace{10pt}
\begin{alertblock}{example}
再给出一种情况,有n堆石子,每次可以从第一堆里去1,2,3颗,可以从第二堆里取奇数颗,第三堆及以后可以取任意颗。
\end{alertblock}
\pause
\vspace{10pt}
$\cdots$紧接着上面的分析:\\
\vspace{6pt}
在求得每个游戏SG值后,然后将所有的异或,也就得到了整体的SG值,这样就可以判断是否有必胜策略了。\\
\pause
\vspace{10pt}
SG函数是让我们遇到看上去很复杂的游戏试图分成若干个子游戏,然后找出最终的SG值,来解决问题。\\
\vspace{6pt}
\pause
当然了,这里的游戏还有很多变型模式,所以SG函数的应用领域就很广泛了。下面就是一个比较好的应用:
\end{frame}
\subsection{Applications}
\begin{frame}
\frametitle{具体应用}
\vspace{12pt}
这里所说的应用主要是在算法上的应用,当然了,博弈还可以用来写象棋程序等。
\begin{alertblock}{problems}
\begin{enumerate}
\item[1$\>$]http://acm.hdu.edu.cn/showproblem.php?pid=1907
\item[2$\>$]http://acm.hdu.edu.cn/showproblem.php?pid=2509
\item[3$\>$]http://acm.hdu.edu.cn/showproblem.php?pid=1536
\item[4$\>$]http://acm.hdu.edu.cn/showproblem.php?pid=1944
\end{enumerate}
\end{alertblock}
\end{frame}
\frame{
\frametitle{Questions and answers}
\begin{figure}
\includegraphics[width=6cm]{faq.jpg}
\end{figure}
}
\end{CJK}
\end{document}
Makefile Introduce
这两天一直在一个大型的分布式存储系统上做工作,今天应该算是初步完工了,提升了初步的编程技能外,一个意外的收获就是对makefile的了解和初步掌握。在这之前,我只写过一个小型的makefile文件,当时是按照网上的资源仿写的,没多太在意,但是通过这次的工作,makefile的重量才在我心里固定下来。
学长给我的学习资料“和我一起写Makefile”(author:陈浩),感觉很不错!接下来,我也要小小的总结下makefile究竟是怎么回事,不涉及具体的写法。
很多Windows程序员都不知道makefile这个东西,因为windows的IDE为你做了这个工作,但是作为一个professional的程序员,这个还是要懂的。“会不会写makefile文件,从一个侧面说明了一个人是否具备完成大型工程的能力。”
我们常常在unix或者linux用到的make其实是一个命令工具,是解释makefile中指令的命令工具,很多IDE都有这个命令。虽然说不同的的环境下,make各不同,但是究其核心,都是“文件依赖”。虽然学过编程语言的人都知道编译和链接,有多少人能很清楚的说明白这个东西呢?
不管怎样,我们先来复习下这个概念。写了一个源文件,首先是将其编译成中间代码文件,在windows下是.obj,在unix下是.o,都是所说的object file;然后将大量的object file合成可执行文件。前者主要是在语法的正确性/函数与变量声明的正确性上做文章;而后者主要是基于object file,链接函数和全局变量,如果找不到函数的实现,就会报错。
类似于很多语言,如latex,python,c,c++等,都有自己一个固定的书写格式,makefile也是这样的,我们可以将makefile作为一种脚本语言。基本的三要素:target(目标文件),prerequisites(依赖项),command(命令)。target可以是一个或多个,依赖于prerequisites,而执行的定义则是在command里的。
最后,要说明一下,make是如何工作的:
1. make会在当前目录下找名字为“Makefile” or “makefile”的文件;
2. 如果找到,它会在文件中的第一个目标文件(target),把其作为最终的目标文件;
3. 如果第一个目标文件不存在或者是其后面依赖项修改了,就会执行command重新生成最终目标文件;(通过更新时间来判断是否是最新的)
4. 如果第一目标文件后的某依赖.o不存在,make会在当前文件中找到该依赖.o,然后利用相应规则生成该.o文件;
5. .o文件后面的依赖项目会是源文件,所以c文件和h文件是不可缺少的。
要注意,make只管文件的依赖项,如果找不到或缺失,是会报错的。
下面是我的一个makefile文件:
AR = ar #ar是默认的函数打包程序;可以声明命令的变量! CC = g++ #命令的变量,编译c++命令 CFLAGS = -g -Wall -fPIC #这是g++的命令参数,-g指的是在编译的时候给出调试信息;-wall生成所有警告信息; OUTPUT := ./encoder ./decoder ./repair INCS_HEAD := ./nlib ./nlib/codes ../../common ../../nandora ../../message ../../client/src ../../ns/src ../../ns/src/btr LIB_PATH := -L ../../lib LIBS := -lclient -lcommon -lmessage -lnandora -lthread -lrt SOURCE := $(wildcard *.cpp) #wildcard意思是所有SOURCE是所有。cpp文件的一个集合 OBJS := $(patsubst %.cpp, %.o, $(SOURCE)) #原型是$(patsubst <pattern>, <replacement>, <text>)模式字符串替换函数, #NOBJS := ./nlib/*.o ./nlib/codes/rc.o NSOURCE := $(wildcard ./nlib/*.cc) ./nlib/codes/rc.cc #定义变量的时候,特别是多个一起并列,中间不用逗号; NOBJS := $(patsubst %.cc, %.o, $(NSOURCE)) LIBOBJS := $(filter-out encoder.o decoder.o repair.o, $(NOBJS) $(OBJS)) #前者过滤掉,防止多个main函数报错,后者是要包含的 ENCODEROBJS := $(filter-out repair.o decoder.o, $(NOBJS) $(OBJS)) DECODEROBJS := $(filter-out encoder.o repair.o, $(NOBJS) $(OBJS)) REPAIROBJS := $(filter-out encoder.o decoder.o, $(NOBJS) $(OBJS)) #:来源,以及操作,注意命令操作时最开始必须有一个tab健;addprefix给每个单词加前缀,-I**; %.o:%.cpp $(CC) $(CFLAGS) $(addprefix -I,$(INCS_HEAD)) -c $< -o $@ all:$(OUTPUT) ./encoder : $(FRCENCODEROBJS) $(CC) $(CFLAGS) $(addprefix -I,$(INCS_HEAD)) $(LIB_PATH) -o $@ $^ $(LIBS) ./decoder : $(FRCDECODEROBJS) $(CC) $(CFLAGS) $(addprefix -I,$(INCS_HEAD)) $(LIB_PATH) -o $@ $^ $(LIBS) ./repair : $(FRCREPAIROBJS) $(CC) $(CFLAGS) $(addprefix -I,$(INCS_HEAD)) $(LIB_PATH) -o $@ $^ $(LIBS) clean: -rm -f $(OBJS) -rm -f $(NOBJS) -rm -f ./nlib/codes/rc.o -rm -f $(OUTPUT)
每种语言都有其固定的一个格式,万变不离其宗。makefile 文件在书写的时候,编译方式、编译格式、输出的目标文件、依赖关系、clean 内容等等,这些一般都是会被包含的内容。每次理解一个makefile文件时,按照这些内容对号入座,问题就变得相对简单了。作为一个初学者,我觉得对文件中相应代码做注释来理解是一个比较好的学习方法。
C++ string && char * && int之间的关系及转换
最近一直在忙别的事情,没有多少时间来写东西,今天算是抽出一点空闲,聒噪一下最近遇到的问题。
开始之前,说下自己的感触。抽象一下计算机or程序,其实你会感觉很简单,输入,处理,输出。在输入这一块里,基本都是字符类型,所以搞清楚如何处理这种类型的数据很重要。甚至从我一直在学习的python来看,这个道理也非常适用!
不说废话了!string其实是作为C++的一个类存在,我们在声明string str的时候,其实就是声明了一个类的对象。这个类有很多内建函数,例如+(链接字符串的操作),length()等等。而char是C/C++的一个基本类型,一个关键字(string不是C++的关键字),char *声明的是一个指针。
因为在使用char *的时候,指针空间大小的分配需要注意,所以string的出现方便了这一系列的问题。至于string如何在char *以及int之间转换,其实也很简单,不过在谈论如何转换前,我们再说下stringstream(流的输入输出操作),它是C++新增的<sstream>库中定义的其中一个类,还有两个类分别是istringstream(流的输入操作), ostringstream(流的输出操作)。需要注意一点的是,<sstream>使用string对象来代替字符数组,这样可以避免缓冲区溢出的危险,而且,传入参数和目标对象的类型被自动推倒出来,即使使用了不正确的格式化符号也没有危险(但是如果你想多次使用同一个stringstream对象,记得每次使用前使用clear()方法——stringstream对象的构造和析构都非常耗用CPU时间,所以这样重复利用比较好)。
int 转 string:
stringstream ss; string str; int n; ss << n; ss << str;
string转int:
string str; int n = atoi(str.c_str());
string转char *:
string str; char *a = str.c_str();
char *转string:
string str; char *a = "abc"; str(a);//初始化即可
atoi()意思是array to int,而c_str()返回的是pointer,所以这里算是比较好理解把。
PS:推荐一个比较好的C++函数以及库的说明查找网站www.cplusplus.com.
你说
你说 我一直叛逆在自己的梦想里
我知道 你知道的知道
所谓的 只是我印在你世界的倒影
而 你知道的不知道
却是我仰望天空时
荡漾在眼睑 那深邃的细腻
文件指针 PK 文件描述符
最近在边看边写一个分布式文件系统的东西。其实对于基本的思路是很明确了,但是单单就在一个文件系统的操作上就耗费了有两个多小时,而且晕了。后来,为了彻底弄清楚,我查阅了很多资料,在这里归纳一下,算是对自己以后的提醒把~!
我们经常看到fopen()或者open()函数,但是具体针对什么情况下使用?这两者的区别又是什么?我们的了解又是多少呢?
解决这个问题之前,我们先说说文件描述符和文件指针的概念。
//FILE的结构
struct_iobuf {
char *_ptr; //缓冲区当前指针
int _cnt;
char *_base; //缓冲区基址
int _flag; //文件读写模式
int _file; //文件描述符
int _charbuf; //缓冲区剩余自己个数
int _bufsize; //缓冲区大小
char *_tmpfname;
};
typedef struct_iobuf FILE;
我们通过上面FILE的结构,可以看到文件描述符是定义在其中的。文件描述符相当于一个逻辑句柄,而open,close等函数是将文件或者物理设备与句柄相联的。在linux中,通常把设备和普通文件都看作是文件,要对文件进行操作就必须先打开文件,打开文件后会得到一个文件描述符,它是一个很小的正整数(声明时是int fid),也是一个索引值;内核会为每一个运行中的进程在进程控制块PCB中维护一个打开的记录表,每一个表项都有一个指针指向打开的文件,上边的索引值是记录表的索引值。如下图示:
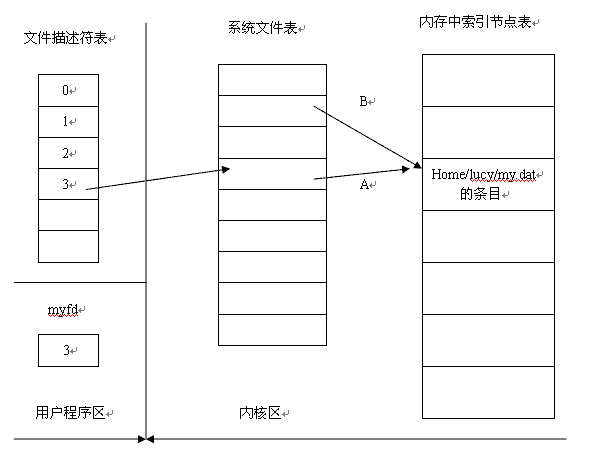
文件描述符兼容POSIX标准,很多系统调用都可以依赖于它,但是缺点也很明显,它不能移植到unix之外的系统上去。
而文件指针是ISO C的标准I/O库中的,类似于unix中使用文件描述符作为文件句柄,C语言使用文件指针(FILE *fp)来作为操作文件的I/O句柄,且文件指针指向的是进程用户空间的一个FILE结构的数据结构(主要包含一个I/O缓冲区和一个文件描述符),所以在某种意义上而言,文件指针就是句柄中的句柄(在windows文件描述符被成为文件句柄)。文件指针的优点是便于移植,且是C语言中的通用格式。
文件描述符是唯一的,但是文件指针却不是唯一的,而其指向的对象是唯一的。既然文件指向一个FILE结构,而FILE结构里又包含有文件描述符,所以在C语言中,文件指针和文件描述符之间是可以相互转换的:
int fileno(FILE * stream) FILE * fdopen(int fd, const char * mode)
总结一下,C语言中使用文件指针对文件操作,对应的库函数分别是fopen(), fclose(), fread(), fwrite(), fscanf(), fprintf()等等,且文件指针有很好的可移植性。而文件描述符是unix系统对文件操作的入口,不具备良好的移植性,对应的I/O函数是open(), close(), read(), write(), ioctl()等。下面是以fopen()和open()函数为例给出的具体区别:
| open() | fopen() |
| 返回文件描述符 | 返回文件指针 |
| 无缓冲 | 有缓冲 |
| 与read()和write()配合使用 | 与fread()和fwrite配合使用 |
我也在网上搜索了一下python的文件操作,比较类似于unix系统,而且在代码的阅读上比较直观,具体可以看一下:
http://www.cnblogs.com/rollenholt/archive/2012/04/23/2466179.html
参考文章链接:
http://www.cnblogs.com/qianye/archive/2012/11/24/2786357.html
http://www.cnblogs.com/hnrainll/archive/2011/08/16/2141354.html
The Asserted Miracles ——Reviewing the Film Forrest Gump
I've been looking for the exact word to make my feelings understood, after mellowing my soul in the pure film Forrest Gump again and again. The last time i immersed myself in the film is two years ago, whereas the soul-touching has endured forever. With a review of the film last night, I couldn't help but to pour out the words swimming in my head.
Every episode of the film does make my soul moisten. His mother's unwavering belief and limitless hope for life enhance my faith in the capricious future; Jenny's tremendous rebel carved deep in her soul urges me to introspect myself; Gump himself strengthens my principle that you will embrace the success sooner or later if you are keen on one orientation and never give up.
"Life is like a box of chocolates, you never know what you are going to get!"
This is Gump's mother's words, which zap the life's myth. Indeed, Gump tends to be himself no matter under what circumstances, he is never oblivious to his own feelings. He just follows his heart, and do whatever he believes to be right. Maybe he is somewhat stupid, but stupid is as stupid does. We can discern a great deal of enlightenment underlying Gump's whole lifestory, whereas for me, I'm blatanly touched by his pure and unadulterated thought. He goes for the choice matches his voice, what's more, once he has set out to do sth., he merely focus himself on it without any distraction, and eventually he makes it. A thing has its cause, the asserted miracles are what you deserve.
Above all, We don’t know if we each have a destiny, or if we’re all just floating around accidental—like on a breeze, but we must keep moving on, and do the best with what God gave you, maybe another miracle would spark tomorrow.
如何做一个更好的Python开发者(2)?(Python Performance Tips, Part 2译)
这一篇是续接“如何做一个更好的Python开发者(1)”的,也就是Python Performance Tips的第二部份。翻译正文如下:
大家需要记住这样一点,即静态编译代码也很重要。例如很多人每天都在使用的Chrome, Firefox, MySQL, MS Office以及Photoshop,它们都是高度优化的软件。Python作为一个解释性的语言,并没有忽视这个事实。在效率至上的某些领域,仅仅使用Python不能符合要求。这就是为什么Python会有基础支持,而这些基础支持往往是通过将繁重的任务转移到用例如C这种较快的语言来实现最底层的东西。对于高效率的计算和嵌入式编程,这是非常关键的一点。Python Performance Tips Part 1讨论了如何将Python使用的更加有效率。在第2部分中,我们会涉及到监控和扩展Python。
1. 首先,抵挡住优化的诱惑。

优化将会给你的原始代码带来复杂性。在你将Python和其他语言整合之前,检查一下是否满足如下一些条件。如果你的解决方法已经足够好,那么优化就不再是那么需要了。
- 你的用户是否记录了速度问题?
- 你能最小化硬盘的I/O量么?
- 你能最小化网络的I/O量么?
- 你能更新提高你的硬件设施么?
- 你为其他开发者写过库么?
- 你的第三方软件是否是最新的?
2. 使用工具监控代码,而不是凭直觉。
速度的问题非常微妙,所以不要凭借直觉。幸好有“cprofiles”这个模块,我们可以通过简单的输入命令来监控Python的代码
“python -m cProfile myprogram.py”
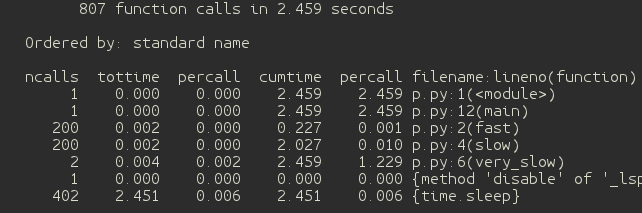
我们写了一个测试程序(如下)。检测结果在上面的黑色块中已经给出了。这里的瓶颈在于对函数“very_slow()”的调用。我们同样也可以看到函数“fast()”和“slow()”都被调用了200次。这意味着如果我们优化函数“fast()”和“slow()”,我们将会得到一个相对更好的效率。而cprofiles模块也可以在执行期间导入。这一点对测试长期运行的进程非常有用。
import time
def fast():
time.sleep(0.001)
def slow():
time.sleep(0.01)
def very_slow():
for i in xrange(100):
fast()
slow()
time.sleep(0.1)
def main():
very_slow()
very_slow()
if __name__ == '__main__':
main()
3. 计算时间复杂度。
经过上面的测试之后,我们可以在解决方案的速度上进行一些基本的分析。常数时间复杂度是最优的情况。对数算法也是很稳定的。阶乘的时间复杂度也不是非常的大。
O(1) -> O(lg n) -> O(n lg n) -> O(n^2) -> O(n^3) -> O(n^k) -> O(k^n) -> O(n!)
4. 使用第三方包。
现在已经存在为Python设计的很多高效库和工具。下面简要列出了一些非常好用的第三方加速包。
- NumPy:一个等价于MatLab的开源包——http://numpy.scipy.org
- SciPy:另一个快捷的计算,工程包——http://scipy.org
- GPULib:使用GPUs为你的代码加速——http://txcorp.com/products/GPULib
- PyPy:优化你的Python代码的及时编译器——http://codespeak.net/pypy
- Cython:将Python代码翻译成C语言——http://cython.org
- ShedSkin:将Python代码翻译成C++语言——http://code.google.com/p/shedskin
5. 在并发情况下使用multiprocessing模块。
因为GIL(Global Interpreter Lock)会将多个线程队列化,所以,在Python中,多线程机制并不能加快你代码在多处理机或集群机下的运行速度。因而Python提供了一个multiprocessing模块,这样以来就可以产生额外的进程而不是线程,优化GIL所带来的限制。另外,你甚至还可以将这个建议和扩展的C代码结合起来,使得你的程序跑的更快。
需要注意的是,进程常常比线程所花费的代价更大,因为线程之间会自动共享内存地址空间和文件描述符。也就是说创建一个进程需要更多的时间,也可能比创建一个线程需要更多的内存空间。所以这也是你在创建进程时所必须考虑的因素。
6. 让我们使用最原始的代码
通过上面的几点,你打算在效率方面使用最原始的代码了么?通过使用标准的ctpyes模块,你可以直接在Python代码中载入编译好的二进制文件(.dll或者.so文件),而不用担心还要写C/C++代码或者构建附属代码。例如,我们写了一个程序,专门用来导入libc生成随即数字。
frome ctypes import *
cdll.LoadLibrary("libc.so.6")
libc = CDLL("libc.so.6")
for i in range(10):
print libc.random() % 10
然而,ctypes的整体捆绑非常严重。你可以将ctypes看作OS库或设备驱动的强力胶。还有其他几个库例如SWIG,Cython以及Boost Python,它们在全局调用上比ctypes少很多。这里我们选择Boost Python库来和Python交互,那是因为Boost Python支持很多面向对象的特性,例如类和继承。如下面的例子,我们保留有常见的C++代码(1~7行),然后在之后导入它(21~24行)。这个例子的主要工作是写一个封装(10~18行)。
/*First write a struct*/
struct Hello {
std::string say_hi()
{
return "Hello World!";
}
}
/*Wrap the Hello struct for Python*/
#include <boost/python.hpp>
using namespace boost::python;
BOOST_PYTHON_MODULE(mymodule)
{
class_<Hello>("Hello")
.def("Say_hi", $Hello::say_hi)
;
}
/*Ready to use in Python*/
import mymodule
hello = mymodule.Hello()
hello.say_hi()
'Hello World!'
结语:
我希望上面写到Python performance系列能使得你成为你一个更好的Python开发者。最后,我还要指出一点,虽然在Python的效率极限上寻找更好的突破是一个非常好玩的事情,但是不成熟的优化可能会反其道而行之。Python在C语言兼容性上提供了很强大的接口,但是我们更希望开发者合理的执行速度优化。你必须问自己,用户是否在你的工作上额外强调了优化的内容。另外,仅仅为节约少量再少量的时间而减少了你代码的可读性是得不偿失的。在一个团队开发中,将代码写的清晰易读是非常重要的。好好利用Python,因为生命是短暂的。
原文出处:http://blog.monitis.com/index.php/2012/03/21/python-performance-tips-part-2/