python PIL 图片处理库
最近学习了 python 的图形处理库 PIL,深刻体会到 python 的强大。就图片的简单处理,如高亮、旋转、resize 等操作,特别是对图片的批量处理,python 较 photoshop 等图片处理工具要来的更容易、更方便。
安装 PIL 库后,根据自己的需求阅读 PIL 库的使用手册。下面是我在使用该 lib 时,遇到的一些问题和感悟。
需求:在图片右上方添加如手机 App 上消息提醒的数字。
具体实现代码如下:
#!/usr/bin/python
import os, sys
from PIL import Image
from PIL import ImageFont
from PIL import ImageDraw
def main():
img = Image.open("thumb.png")
fontsize = img.size[1] / 16
x = img.size[0] - fontsize
draw = ImageDraw.Draw(img)
font = ImageFont.truetype("/usr/share/fonts/truetype/msttcorefonts/arial.ttf", fontsize)
draw.text((x, 0), "9", font=font, fill="red")
del draw
img.save("result.png")
img.show()
if __name__== '__main__':
main()
分析:
1. 坐标 (0, 0) 表示左上角,整个图片类似镶嵌在坐标的第四像限;img.size 是一个二位数组,依次位图片的宽和高。
2. 在图片上添加内容时注意对应内容也会占位置,所以不能当作点即 pixel 来看待,实际处理时需要考虑添加对象的 size,这就对应代码中右上角坐标 x 的获取。
3. ImageFont 的获取有很多方法,其中较简单的方法从 truetype 中获取,对应 font 存放的位置一般是 /usr/share/fonts/...
python中a.any()以及&&,||
首先说明一下,在python中是没有&&及||这两个运算符的,取而代之的是英文and和or。其他运算符没有变动。
接着重点要说明的是python中的a.any(),我之所以会涉及到这个函数,是因为我在设计某个分段数值函数时由于不细心犯的错误引起的。a.any(),根据官方解释:
Test whether any elements of an array evaluate to True along an axis.
即针对的是一个list,判断list中的某个元素是否为真,此时只要有一个元素为真,list元素全部输出。下面一个例子更直观的做了解释:
#!/usr/bin/python
#coding=utf8
import numpy as np
def f(data):
for val in data:
if val <= 0.6:
r1 = val*1
print "this is <= 0.6 numbers", r1
if val > 4:
r1 = val*1
print "this is > 4 numbers ", r1
def main():
data = np.arange(0.1, 5.1, 0.5)
if np.any(data > 0.3) and np.any(data <= 1):
r1 = data * 1
print r1
f(data)
if __name__=='__main__':
main()
对应的输出是:
[ 0.1 0.6 1.1 1.6 2.1 2.6 3.1 3.6 4.1 4.6] this is <= 0.6 numbers 0.1 this is <= 0.6 numbers 0.6 this is > 4 numbers 4.1 this is > 4 numbers 4.6
在a.any()中,只要满足条件,整个list就是true的。而我在分段函数计算时,恰恰使用到了a.any()来判断list的范围,在后面的计算中,其实是整个list同时运算然后赋值了,也就将分段函数结果简化成了某一段的所有值。正确的计算分段函数有两中策略,要么像上面的函数f(),要么将list分段带入运算。
这个问题我纠结了一个晚上,最后才发现是a.any()的问题。最开始使用的时候,其真正的用法没有具体熟悉,同时我也该反省我自己,对python语言掌握的实在太菜了!
路漫漫其修远兮,吾将上下而求索~
python绘制数学图形(堪比matlab)
在开始之前,我要对latex做一点补充。
上一篇文章中提到了latex绘制流程图,文中给出了一个实例,在具体的应用上也很简单。下面两个网页可能会比较有用,特别是在流程图的绘制上(各类shapes汇总):
http://www.texample.net/tikz/examples/feature/nodes-and-shapes/
流程图判断——菱形,其变扁的方法:
http://bbs.ctex.org/forum.php?mod=viewthread&tid=57980
下面开始今天要说到的主题。matlab固然很牛叉,但是在理解和实现上还是相对复杂的,python利用现有的库,基本可以实现matlab所有的功能,甚至超越之。与前面的文章相对应,python绘图应该主要着眼的是一些比较严谨的数学公式的绘制问题,相对于latex,其图形更加有数学之美。
今天晚上,我又整了一下python的绘图,感觉还是比较方便的,50行不到的代码即可实现比较完美的图形,特别推荐。下面对应的依次是图形和代码:
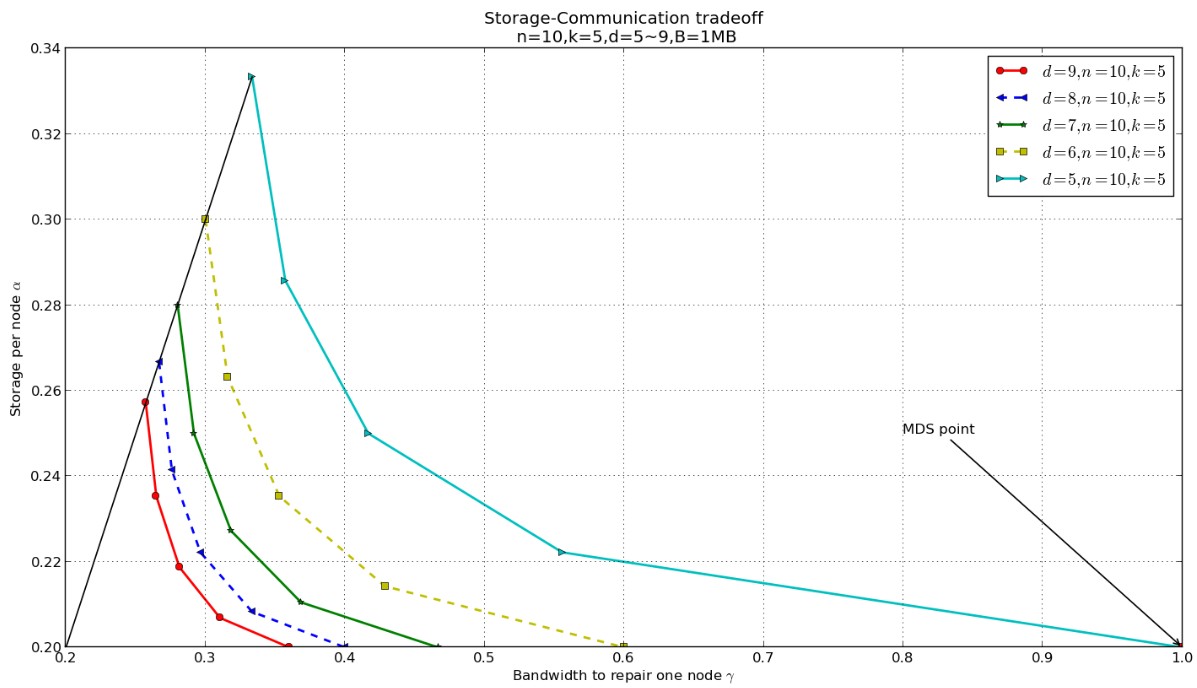
对应的代码很简单:
#!/usr/bin/python
#coding = utf8
import sys
import string
import numpy as np
import matplotlib.pyplot as plt
def f_fun(d, k, i):
a = (2.0*d)/((2.0*k-i-1.0)*i+2.0*k*(d-k+1.0))
return a
def g_fun(d, k, i):
a = (2.0*d-2.0*k+i+1.0)*i*1.0/(2.0*d)
return a
def main():
form = ['ro-', 'b--<', 'g-*', 'y--s', 'c->']
k = 5
d = [9, 8, 7, 6, 5]
x = y = [1.0/k]
for t in range(5):
r = [f_fun(d[t], k, i) for i in range(k-1, -1, -1)]
a = [((1.0-g_fun(d[t], k, i)*r[k-i-1])*1.0/(k-i)) for i in range(k-1, 0, -1)]
a.append(1.0/k)
x.append(r[0])
y.append(a[0])
plt.plot(r, a, form[t], linewidth = 2.0, label = "$d="+str(d[t])+",n=10,k=5$")
plt.plot(x, y, linewidth = 1.2, color = 'black')
plt.plot([1.0], [1.0/k], 'rs')
plt.annotate("MDS point", xy=(1.0, 1.0/k), xycoords = 'data', xytext=(0.8, 0.25), arrowprops=dict(arrowstyle="->", linewidth = 1.2))
#plt.plot([1.0], [1.0/k], 'rs')
plt.legend(loc='upper right')
plt.title("Storage-Communication tradeoff \n n=10,k=5,d=5~9,B=1MB")
plt.ylabel("Storage per node $\\alpha$")
plt.xlabel("Bandwidth to repair one node $\\gamma$")
plt.grid(True)
plt.show()
if __name__ == '__main__':
main()
如何做一个更好的Python开发者(2)?(Python Performance Tips, Part 2译)
这一篇是续接“如何做一个更好的Python开发者(1)”的,也就是Python Performance Tips的第二部份。翻译正文如下:
大家需要记住这样一点,即静态编译代码也很重要。例如很多人每天都在使用的Chrome, Firefox, MySQL, MS Office以及Photoshop,它们都是高度优化的软件。Python作为一个解释性的语言,并没有忽视这个事实。在效率至上的某些领域,仅仅使用Python不能符合要求。这就是为什么Python会有基础支持,而这些基础支持往往是通过将繁重的任务转移到用例如C这种较快的语言来实现最底层的东西。对于高效率的计算和嵌入式编程,这是非常关键的一点。Python Performance Tips Part 1讨论了如何将Python使用的更加有效率。在第2部分中,我们会涉及到监控和扩展Python。
1. 首先,抵挡住优化的诱惑。

优化将会给你的原始代码带来复杂性。在你将Python和其他语言整合之前,检查一下是否满足如下一些条件。如果你的解决方法已经足够好,那么优化就不再是那么需要了。
- 你的用户是否记录了速度问题?
- 你能最小化硬盘的I/O量么?
- 你能最小化网络的I/O量么?
- 你能更新提高你的硬件设施么?
- 你为其他开发者写过库么?
- 你的第三方软件是否是最新的?
2. 使用工具监控代码,而不是凭直觉。
速度的问题非常微妙,所以不要凭借直觉。幸好有“cprofiles”这个模块,我们可以通过简单的输入命令来监控Python的代码
“python -m cProfile myprogram.py”
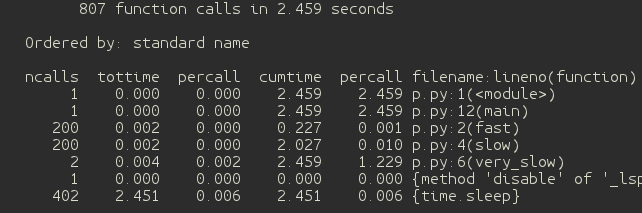
我们写了一个测试程序(如下)。检测结果在上面的黑色块中已经给出了。这里的瓶颈在于对函数“very_slow()”的调用。我们同样也可以看到函数“fast()”和“slow()”都被调用了200次。这意味着如果我们优化函数“fast()”和“slow()”,我们将会得到一个相对更好的效率。而cprofiles模块也可以在执行期间导入。这一点对测试长期运行的进程非常有用。
import time
def fast():
time.sleep(0.001)
def slow():
time.sleep(0.01)
def very_slow():
for i in xrange(100):
fast()
slow()
time.sleep(0.1)
def main():
very_slow()
very_slow()
if __name__ == '__main__':
main()
3. 计算时间复杂度。
经过上面的测试之后,我们可以在解决方案的速度上进行一些基本的分析。常数时间复杂度是最优的情况。对数算法也是很稳定的。阶乘的时间复杂度也不是非常的大。
O(1) -> O(lg n) -> O(n lg n) -> O(n^2) -> O(n^3) -> O(n^k) -> O(k^n) -> O(n!)
4. 使用第三方包。
现在已经存在为Python设计的很多高效库和工具。下面简要列出了一些非常好用的第三方加速包。
- NumPy:一个等价于MatLab的开源包——http://numpy.scipy.org
- SciPy:另一个快捷的计算,工程包——http://scipy.org
- GPULib:使用GPUs为你的代码加速——http://txcorp.com/products/GPULib
- PyPy:优化你的Python代码的及时编译器——http://codespeak.net/pypy
- Cython:将Python代码翻译成C语言——http://cython.org
- ShedSkin:将Python代码翻译成C++语言——http://code.google.com/p/shedskin
5. 在并发情况下使用multiprocessing模块。
因为GIL(Global Interpreter Lock)会将多个线程队列化,所以,在Python中,多线程机制并不能加快你代码在多处理机或集群机下的运行速度。因而Python提供了一个multiprocessing模块,这样以来就可以产生额外的进程而不是线程,优化GIL所带来的限制。另外,你甚至还可以将这个建议和扩展的C代码结合起来,使得你的程序跑的更快。
需要注意的是,进程常常比线程所花费的代价更大,因为线程之间会自动共享内存地址空间和文件描述符。也就是说创建一个进程需要更多的时间,也可能比创建一个线程需要更多的内存空间。所以这也是你在创建进程时所必须考虑的因素。
6. 让我们使用最原始的代码
通过上面的几点,你打算在效率方面使用最原始的代码了么?通过使用标准的ctpyes模块,你可以直接在Python代码中载入编译好的二进制文件(.dll或者.so文件),而不用担心还要写C/C++代码或者构建附属代码。例如,我们写了一个程序,专门用来导入libc生成随即数字。
frome ctypes import *
cdll.LoadLibrary("libc.so.6")
libc = CDLL("libc.so.6")
for i in range(10):
print libc.random() % 10
然而,ctypes的整体捆绑非常严重。你可以将ctypes看作OS库或设备驱动的强力胶。还有其他几个库例如SWIG,Cython以及Boost Python,它们在全局调用上比ctypes少很多。这里我们选择Boost Python库来和Python交互,那是因为Boost Python支持很多面向对象的特性,例如类和继承。如下面的例子,我们保留有常见的C++代码(1~7行),然后在之后导入它(21~24行)。这个例子的主要工作是写一个封装(10~18行)。
/*First write a struct*/
struct Hello {
std::string say_hi()
{
return "Hello World!";
}
}
/*Wrap the Hello struct for Python*/
#include <boost/python.hpp>
using namespace boost::python;
BOOST_PYTHON_MODULE(mymodule)
{
class_<Hello>("Hello")
.def("Say_hi", $Hello::say_hi)
;
}
/*Ready to use in Python*/
import mymodule
hello = mymodule.Hello()
hello.say_hi()
'Hello World!'
结语:
我希望上面写到Python performance系列能使得你成为你一个更好的Python开发者。最后,我还要指出一点,虽然在Python的效率极限上寻找更好的突破是一个非常好玩的事情,但是不成熟的优化可能会反其道而行之。Python在C语言兼容性上提供了很强大的接口,但是我们更希望开发者合理的执行速度优化。你必须问自己,用户是否在你的工作上额外强调了优化的内容。另外,仅仅为节约少量再少量的时间而减少了你代码的可读性是得不偿失的。在一个团队开发中,将代码写的清晰易读是非常重要的。好好利用Python,因为生命是短暂的。
原文出处:http://blog.monitis.com/index.php/2012/03/21/python-performance-tips-part-2/
如何做一个更好的Python开发者(1)?(Python Performance Tips, Part 1译)
从最开始的写python代码到现在,其实还没有对如何更好的开发python代码有一个全新的认识,这片文章是我翻译一个大牛中的大牛给Python写的tips。正文如下:
如果你想要阅读Zen of Python,只需要在你的Python解释器里键入import this。对于刚刚接触python的人,如果心细,就会注意到“解释器”这个词,随即也会意识到Python是另一种脚本语言。“它肯定很慢!”这种观点毫无疑问是正确的:Python程序不像编译语言那样高效。甚至Python的倡导者也会告诉你Pyhton语言在效率方面处于劣势。然而,YouTube已经证明,Python在每个小时内能提供4000万视频的服务。你必须做的所有事情就是写出高效的代码,在速度要求方面寻找C/C++的外部实现。这里有一些tips可以帮助你成为一个更好的Python开发者:
1. 选择内建函数:
你可以使用Python写高效的代码,但是你却很难避免用到内建函数(用C语言完成的)。点击这里察看。这写内建函数非常快。
2. 使用join()函数将大量的字符串连起来:
你能使用符号“+”将几个字符串结合起来。因为字符串是不可改变的,每个涉及到“+”的操作都会创建一个新的字符串,同时拷贝旧字符串的内容。一种应用频度非常高的惯用语法是利用Python的数组模式修改单个字符;接着就是使用join()函数再创建你最终的字符串。
#This is good to glue a large number of strings
for chunk in input():
my_string.join(chunk)
3. 在交换变量值中使用多重赋值:
这种方式在Python中是非常快捷的:
x, y = y, x
而下面这种方式要慢很多:
temp = x x = y y = temp
4. 尽可能使用临时变量:
Python检索临时变量的速度要比检索全局变量快。所以,尽量避免使用“global”这个关键词。
5. 尽可能的使用“in”:
一般在检查成员关系时,会用到关键词“in”。这种方式很简洁,也很快捷。
for key in sequence:
print "found"
6. 通过懒惰方式的importing提高速度:
将“import”语句移到函数中去,这样你就只会在用到的时候import某些内容。也就是说,如果有些模块你不是马上用到,你就可以晚些import它们。例如,在启动的时候,你可以先不import一长列的模块来提高你代码的速度。这个技术没有加强全局的效率。但是它帮助你将导入模块的时间更加均匀的分布在代码中。
7. 在无限循环中使用“while 1”:
有时候你会在你的代码中使用到无限循环。(例如,一个监听socket)虽然“while True”实现了同样的功能,但是,“while 1”是一个单独的跳操作。你可以将这个trick用在你高效的Python代码中。
while 1:
#do stuff, faster with while 1
while True:
#do stuff, slower with while True
8. 使用list内涵:
在Python2.0之后,你就可以使用list内涵代替很多“for”和“while”块。list内涵更快的原因在于,在循环的过程中,Python解释器能最优的发现一个可预测的模式。一方面,list内涵更加易读(函数编程中),另一方面,它为你节约了一个额外的计数变量。例如,我们可以在一行内得到1到10之间的偶数数值:
#the good way to iterate a range
evens = [i fo i in range(10) if i % 2 == 0]
[0, 2, 4, 6, 8]
#the following is not so Pythonic
i = 0
evens = []
while i < 10:
if i % 2 == 0: evens.append(i)
i += 1
[0, 2, 4, 6, 8]
9. 在每个长序列中使用xrange():
这样做可以为你节约大量的系统内存空间,因为xrange()每次只在一个序列中产生一个整数元素。和range()相反,它给出你整个列表,而这在整体的循环中是不必要的。
10. 根据需求,使用Python生成器得到相应的数值:
这种做法同样可以节约内存空间,提高代码效率。如果你在传输视频的数据流,你能send一个chunk的字节,而不是整个数据流。例如,
chunk = (1000 * i for i in xrange(1000)) chunk <generator object <genexpr> at 0x7f65d90dcaa0> chunk.next() 0 chunk.next() 1000 chunk.next() 2000
11. 学习itertools模块:
这个模块在迭代和聚合方面非常高效。通过三行代码我们就可以得到list[1, 2, 3]的所有排列:
import itertools iter = itertools.permutations([1, 2, 3]) list(iter) [(1, 2, 3), (1, 3, 2), (2, 1, 3), (2, 3, 1), (3, 1, 2), (3, 2 ,1)]
12. 学习bisect模块将list保持有序:
这是一个开源的二叉查找实现,同时也是一个很快的有序序列插入工具。也就是说,你能这样使用:
improt bisect bisect.insort(list, element)
通过上面的操作,你就在list中插入了一个元素,接下来你也不需要再次调用sort()函数来保持有序,我们也必须注意到后者在长序列中的代价是非常高的。
13. 需要理解,一个Pyhon列表其实就是一个数组:
Python中的列表实现和人们在Computer science中谈到的一般独立链接列表是不一样的。Python的列表其实是一个数组。这样一来,你就可以以O(1)的时间,利用下标索引,很快搜索到列表中的一个元素,而不需要从列表的开始处搜索。这点意味着什么呢?一个Python的开发者在使用insert()函数插入一个list元素时需要三思。例如:list.insert(0, element)
在list的首部插入一个元素并不是一个高效的选择,因为这个list中所有的其他下标都会改变。然而你可以将一个元素高效的添加到list尾部,利用函数list.append()。如果你确实想要更快的插入或者删除两端的元素,最好选择双端队列deque。因为deque在Python中是作为双向链表来实现的,所以它会更快一些。这里不再做过多的赘述。
14. 使用dict和set检测成员关系:
Python的dict和set在检查一个元素是否存在时非常快捷。因为这两者是利用hash表来实现的。它们的查找时间可以达到O(1)。因此,如果你要经常检查成员关系,最好使用dict或者set。
mylist = ['a', 'b', 'c'] #Slower, check membership with list: 'c' in mylist True myset = set(['a', 'b', 'c']) #Faster, check membership with set: 'c' in myset: True
15. 在sort()函数中兼并使用Schwartzian Transform:
list.sort()函数在处理数据方面是非常快的。它会将一个list处理得到一个自然顺序的列表。然而,你有时候想要得到非自然序列的list。例如,你想要将IP地址根据你服务器的位置来排序。Python支持传统的比较,也就是说你可以使用list.sort(cmp())函数来实现,但是这样做会比list.sort()慢很多,因为你引入该函数调用了上层的内容。如果速度需要考虑进来,你可以使用在Schwartzian Transform算法的基础之上产生的Guttman-Rosler Transform算法。可以读到其具体如何实现的算法当然是非常有趣的,这里我们对其如何工作的只做一个简单的总结,你可以通过调用Python的内建函数list.sort()快速转换list,而不需要使用相对时间较慢的list.sort(cmp())函数。
16. 使用Python的decorator缓存结果:
符号“@”是Python的点缀(decorator)语法。不仅仅可以使用它来跟踪,上锁or记录日志。你甚至可以点缀Python的函数,使其记住接下来会使用到的结果。这个技术被称之为memoization。接下来有一个例子:
from functools import wraps
def memo(f):
cache = {}
@wraps(f)
def wrap(*arg):
if arg not in cache: cache['arg'] = f(*arg)
return cache['arg']
return wrap
我们也可以将点缀用在Fibonacci函数中
@memo
def fib(i):
if i < 2: return 1
return fib(i - 1) + fib(i - 2)
这里的主要目的很简单:增强(or decorate)你的函数,使其记住已经计算得到的每个Fibonacci元素。如果这些值都在缓存中,也就没有必要再次计算。
17. 理解Python的GIL(全局解释器锁global interpreter lock):
GIL是非常必要的,因为CPython的内存处理并不具有线程安全性。你不能简单的创建多个线程,然后希望Python会在多核机器上跑的非常快。这是因为GIL将会防止多个本地线程一次执行Python的多个字节码。也就是说,GIL会将你的所有线程系列化。然而,你可以通过使用多线程协调几个已创建的且独立运行于Python代码之外的进程,加速代码运行效率。
18. 将Python源代码作为你的文档:
Python有很多考虑到速度而使用C语言实现的模块。当效率在编码中非常重要时,官方的文档就会显得匮乏,此时你可以自由的去体验源代码。而在这个过程中你会发现很多潜在的数据结构和算法。Python仓库是一个非常美妙的地方,也很值得在其中徜徉:http://svn.python.org/view/python/trunk/Modules
结语:
世界上没有大脑的替代物。程序开发者的责任是深刻的看清楚问题,达到不会轻易的将一个坏的构思集合在一起的境界。这篇文章里关于Python的tips能帮助你获得更好的效率。如果速度仍然不是足够的优,此时Python需要寻求额外的帮助:编写以及运行外部扩展代码。我们将会在这片文章的第二部份涉及到这一块。
To be continued...
(原文链接:http://blog.monitis.com/index.php/2012/02/13/python-performance-tips-part-1/)
从python文件提取以及绘图谈其设计思想
我最近对python特别着迷,学会爬虫抓取数据之后,接着尝试将抓取到的文件数据提取,然后绘制出走势图,后面的这个任务的完成,我用了整整一个下午的时间(不睡午觉),但是最后在代码以及变量函数命名方面做的诸多不足,下面给出我前后代码,谈谈python的设计思想
主模块:
#!/usr/bin/python
# coding = utf-8
import sys
import string
import matplotlib.pyplot as plt
import numpy as np
import getNum #获得歌曲排名,因为设计中文编码问题,单独作为一个自定义模块
def getKey(fileName, s, dist):
f = open(fileName, "r")
info = f.read()
f.close()
start = info.find(s) + dist
info = info[start:]
end = info.find(",")
return info[:end]
def songDraw():
x = np.arange(1, 8, 1)
c = ('y', 'b', 'g', 'r', 'c', 'y', 'b', 'g', 'r', 'c')
fileDay = ("day1.txt", "day2.txt", "day3.txt", "day4.txt", "day5.txt", "day6.txt", "day7.txt")
for i in range(0, 10, 1):
num = []
tmp = str(i * 20 + 1)
strlen = len(tmp)
if strlen == 1:#歌曲的位数要考虑,这样每次截取得到的才是正确的
dist = 2
elif strlen == 2:
dist = 3
else:
dist = 4
key = getKey("day1.txt", tmp, dist)
num.append(i * 20 + 1)
for j in range(1, 7, 1):
num.append(int(getNum.getY(fileDay[j], key)))
print num
if i < 5:
plt.plot(x, num, color=c[i], label="Monday's rank NO."+tmp)
else:
plt.plot(x, num, linestyle='--', color=c[i], label="Monday's rank NO."+tmp)
# plt.plot(x, num, color=c[i], label=u(key))
plt.legend(loc='upper right')
plt.title("The song's seven-day rank")
plt.xlabel("days")
plt.ylabel("rank")
plt.grid(True)
plt.show()
if __name__ == '__main__':
songDraw()
主模块使用到的自定义模块:
#!/usr/bin/python
# -*- coding:gbk -*-
import string
def getY(fileName, key):
f = open(fileName, "r")
info = f.read()
f.close()
#print s
end = info.find(key) - 1
if end == -2:
return 0
else:
info = info[:end]
info = info[::-1]#将字符串反转,从最后面取值
end = info.find(",")
info = info[:end]
#print tmp
return info[::-1]
接下来的是修改之后的:
#!/usr/bin/python
# coding = utf-8
import sys
import string
import matplotlib.pyplot as plt
import numpy as np
def getSongName(file_name, rank):
info = open(file_name, "r").read()
start = info.find(rank)
return info[start:].split(',')[1]
def getSongRank(file_name, songName):
info = open(file_name, 'r').read()
end = info.find(songName)
if end == -1:
return 201
else:
return int(info[:end].split(',')[-2])#使用split之后,函数反转不需要了,中文字符的查找问题也不存在了
def songDraw():
x = np.arange(1, 8)
c = ('y', 'b', 'g', 'r', 'c', 'y', 'b', 'g', 'r', 'c')
fileDay = ("day1.txt", "day2.txt", "day3.txt", "day4.txt", "day5.txt", "day6.txt", "day7.txt")
for i in range(10):
songName = getSongName("day1.txt", str(i * 20 + 1))
num = [getSongRank(fileDay[j], songName) for j in range(7)]#简化的一个亮点
print num
if i < 5:
plt.plot(x, num, color=c[i])
else:
plt.plot(x, num, linestyle='--', color=c[i])
plt.title("The song's seven-day rank")
plt.xlabel("days")
plt.ylabel("rank")
plt.grid(True)
plt.show()
if __name__ == '__main__':
songDraw()
可以看到,两者之间有非常明显的区别。前后代码量以及松散程度得到了很好的对比。作为一个菜鸟,感觉对python最重要的三大数据结构list,string以及字典使用的还是不到位,不过通过这个训练过程,我至少学会了如何去调试python。同时,在命名规范上,我要做到更加简洁明了。
其实之前写的C代码多了,所以总感觉在for循环里计算的东西能放在外面就放在外面,经高人提点,python最初的设计理念就不是这样的。python作为一种解释执行的编程语言,其最大的优点之一是它使你能够专注于解决问题而不是去搞明白语言本身。作为每一个python代码的书写者,都要牢记简洁是python的一大美,简洁才能做到易读易看,简洁才能让自己的代码更加优美,不会太慵懒!在网上搜了下——python之禅:
- 优美胜于丑陋(Python 以编写优美的代码为目标)
- 明了胜于晦涩(优美的代码应当是明了的,命名规范,风格相似)
- 简洁胜于复杂(优美的代码应当是简洁的,不要有复杂的内部实现)
- 复杂胜于凌乱(如果复杂不可避免,那代码间也不能有难懂的关系,要保持接口简洁)
- 扁平胜于嵌套(优美的代码应当是扁平的,不能有太多的嵌套)
- 间隔胜于紧凑(优美的代码有适当的间隔,不要奢望一行代码解决问题)
- 可读性很重要(优美的代码是可读的)
通过这次的经历,感触还是蛮多的,在代码的技巧以及书写方面也深深觉察到自己的不足,前面的一段路还是很长啊!不过我会加油的,每天进步一点就够了!
urllib2.URLError: <urlopen error [Errno 111] Connection refused>
在说道这个问题之前,我想先说下python中的str.find()函数,因为我几次用到这个函数时,都有点出了乱子。
str.find()查找的是一个长字符串中的子串,看如下一个例子的输出:
1 #!/usr/bin/python
2 #coding = utf-8
3
4 import string
5 import sys
6
7 def main():
8 s = "Today is Friday, I am so happy!"
9 print s.find("I")
10 print s.find("I am")
11
12 if __name__ == '__main__':
13 main()
结果都是17,所以要知道,这里find匹配的是最开始的一个独立成的字符!!!这样以来,我们在分析网页的时候就要注意这个问题了!
下面开始说下我遇到的问题,urllib2.URLError: <urlopen error [Errno 111] Connection refused>。我测试了好久,甚至运行了之前可以运行成功的python代码,但是最后都以失败告终。
这里要注意,我们通过这个库可以得到网络上的资源(一个url对应的就是一个资源,要区分ping,ip以及url的区别),只是connection有问题,查阅了很多资料,最后发现是我的电脑上安装了一个代理工具goagent。在最后具体解决的时候是每次将代理打开之后再运行python代码,抓取成功了。
PS:虽然最后成功了,但是我还是不太明白,我的默认浏览器没有设置代理,为什么urllib2在获取网络资源的时候仍然要通过代理呢??我也看了urllib2的相关资料,猜测可能是该库在具体的实现上有代理起优先的算法把?--------有待解决!!
网页抓取中编码问题:UnicodeEncodeError: ‘gbk’ codec can’t encode character ****: illegal multibyte sequence
“UnicodeEncodeError: ‘gbk’ codec can’t encode character ****: illegal multibyte sequence”
上面这个问题是我在练习写python脚本抓取网页信息的时候,遇到的问题!我很郁闷,因为通过察看page info发现它现实的网页编码方式确实是gbk,我的处理是这样的:
def getResult(url):
txtfile = open("cnbeta.txt", "w")
html = urllib2.urlopen(url).read()
html = html.decode('gbk').encode('utf-8')
#print html
analysisPage(html, txtfile)
txtfile.close()
后来甚至将gbk改成gbk1213,gb等等编码方式,都显示错误,查了很多资料都不对。我甚至想到用另一种方式来抓取,但是不经意的搜网页,我发现这样可以解决:
def getResult(url):
txtfile = open("cnbeta.txt", "w")
html = urllib2.urlopen(url).read()
html = html.decode('gbk', 'ignore').encode('utf-8')
#print html
analysisPage(html, txtfile)
txtfile.close()
这段代码只需要修改一点点就ok了。分析原因:
在代码的整体实现上是没有问题的,主要是遇到了非法字符--------特别是在全角空格的问题上,因为其实现方式有很多种,比如\xa3 \xa0,或者\xa4\xa5,这写字符,看起来都像是全角空格,但是他们不是合法的(真正的全角空格是\xa1\xa1),因此在码的转换中出现了问题。而且这样的问题一出现,就会导致整个文件都不能转换。
这时,就不要忘了,decode的函数原型:decode([encoding], [errors='strict'])。默认参数是strict,代表遇到非法字符抛出异常;如果是ignore,则会忽略,直接输出;如果是replace,则会用?取代非法字符;如果设置成xmlcharrefreplace,则使用XML字符引用。
(全文参考:http://www.cnblogs.com/baiyuyang/archive/2011/10/29/2228667.html)