如何做一个更好的Python开发者(2)?(Python Performance Tips, Part 2译)
这一篇是续接“如何做一个更好的Python开发者(1)”的,也就是Python Performance Tips的第二部份。翻译正文如下:
大家需要记住这样一点,即静态编译代码也很重要。例如很多人每天都在使用的Chrome, Firefox, MySQL, MS Office以及Photoshop,它们都是高度优化的软件。Python作为一个解释性的语言,并没有忽视这个事实。在效率至上的某些领域,仅仅使用Python不能符合要求。这就是为什么Python会有基础支持,而这些基础支持往往是通过将繁重的任务转移到用例如C这种较快的语言来实现最底层的东西。对于高效率的计算和嵌入式编程,这是非常关键的一点。Python Performance Tips Part 1讨论了如何将Python使用的更加有效率。在第2部分中,我们会涉及到监控和扩展Python。
1. 首先,抵挡住优化的诱惑。

优化将会给你的原始代码带来复杂性。在你将Python和其他语言整合之前,检查一下是否满足如下一些条件。如果你的解决方法已经足够好,那么优化就不再是那么需要了。
- 你的用户是否记录了速度问题?
- 你能最小化硬盘的I/O量么?
- 你能最小化网络的I/O量么?
- 你能更新提高你的硬件设施么?
- 你为其他开发者写过库么?
- 你的第三方软件是否是最新的?
2. 使用工具监控代码,而不是凭直觉。
速度的问题非常微妙,所以不要凭借直觉。幸好有“cprofiles”这个模块,我们可以通过简单的输入命令来监控Python的代码
“python -m cProfile myprogram.py”
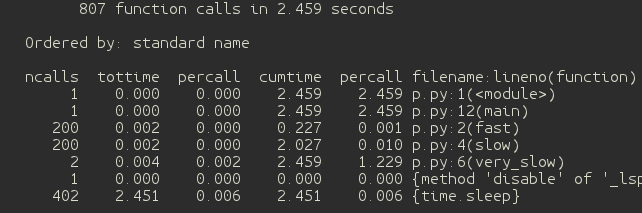
我们写了一个测试程序(如下)。检测结果在上面的黑色块中已经给出了。这里的瓶颈在于对函数“very_slow()”的调用。我们同样也可以看到函数“fast()”和“slow()”都被调用了200次。这意味着如果我们优化函数“fast()”和“slow()”,我们将会得到一个相对更好的效率。而cprofiles模块也可以在执行期间导入。这一点对测试长期运行的进程非常有用。
import time
def fast():
time.sleep(0.001)
def slow():
time.sleep(0.01)
def very_slow():
for i in xrange(100):
fast()
slow()
time.sleep(0.1)
def main():
very_slow()
very_slow()
if __name__ == '__main__':
main()
3. 计算时间复杂度。
经过上面的测试之后,我们可以在解决方案的速度上进行一些基本的分析。常数时间复杂度是最优的情况。对数算法也是很稳定的。阶乘的时间复杂度也不是非常的大。
O(1) -> O(lg n) -> O(n lg n) -> O(n^2) -> O(n^3) -> O(n^k) -> O(k^n) -> O(n!)
4. 使用第三方包。
现在已经存在为Python设计的很多高效库和工具。下面简要列出了一些非常好用的第三方加速包。
- NumPy:一个等价于MatLab的开源包——http://numpy.scipy.org
- SciPy:另一个快捷的计算,工程包——http://scipy.org
- GPULib:使用GPUs为你的代码加速——http://txcorp.com/products/GPULib
- PyPy:优化你的Python代码的及时编译器——http://codespeak.net/pypy
- Cython:将Python代码翻译成C语言——http://cython.org
- ShedSkin:将Python代码翻译成C++语言——http://code.google.com/p/shedskin
5. 在并发情况下使用multiprocessing模块。
因为GIL(Global Interpreter Lock)会将多个线程队列化,所以,在Python中,多线程机制并不能加快你代码在多处理机或集群机下的运行速度。因而Python提供了一个multiprocessing模块,这样以来就可以产生额外的进程而不是线程,优化GIL所带来的限制。另外,你甚至还可以将这个建议和扩展的C代码结合起来,使得你的程序跑的更快。
需要注意的是,进程常常比线程所花费的代价更大,因为线程之间会自动共享内存地址空间和文件描述符。也就是说创建一个进程需要更多的时间,也可能比创建一个线程需要更多的内存空间。所以这也是你在创建进程时所必须考虑的因素。
6. 让我们使用最原始的代码
通过上面的几点,你打算在效率方面使用最原始的代码了么?通过使用标准的ctpyes模块,你可以直接在Python代码中载入编译好的二进制文件(.dll或者.so文件),而不用担心还要写C/C++代码或者构建附属代码。例如,我们写了一个程序,专门用来导入libc生成随即数字。
frome ctypes import *
cdll.LoadLibrary("libc.so.6")
libc = CDLL("libc.so.6")
for i in range(10):
print libc.random() % 10
然而,ctypes的整体捆绑非常严重。你可以将ctypes看作OS库或设备驱动的强力胶。还有其他几个库例如SWIG,Cython以及Boost Python,它们在全局调用上比ctypes少很多。这里我们选择Boost Python库来和Python交互,那是因为Boost Python支持很多面向对象的特性,例如类和继承。如下面的例子,我们保留有常见的C++代码(1~7行),然后在之后导入它(21~24行)。这个例子的主要工作是写一个封装(10~18行)。
/*First write a struct*/
struct Hello {
std::string say_hi()
{
return "Hello World!";
}
}
/*Wrap the Hello struct for Python*/
#include <boost/python.hpp>
using namespace boost::python;
BOOST_PYTHON_MODULE(mymodule)
{
class_<Hello>("Hello")
.def("Say_hi", $Hello::say_hi)
;
}
/*Ready to use in Python*/
import mymodule
hello = mymodule.Hello()
hello.say_hi()
'Hello World!'
结语:
我希望上面写到Python performance系列能使得你成为你一个更好的Python开发者。最后,我还要指出一点,虽然在Python的效率极限上寻找更好的突破是一个非常好玩的事情,但是不成熟的优化可能会反其道而行之。Python在C语言兼容性上提供了很强大的接口,但是我们更希望开发者合理的执行速度优化。你必须问自己,用户是否在你的工作上额外强调了优化的内容。另外,仅仅为节约少量再少量的时间而减少了你代码的可读性是得不偿失的。在一个团队开发中,将代码写的清晰易读是非常重要的。好好利用Python,因为生命是短暂的。
原文出处:http://blog.monitis.com/index.php/2012/03/21/python-performance-tips-part-2/
2024年2月22日 18:36
Good post. Thanks for sharing with us. I just loved your way of presentation. I enjoyed reading this .Thanks for sharing and keep writing