一位研究生的学习感悟——采撷篇
由于现实世界太过于复杂而且充满不确定性,远非有限的生命用经验能够理解,因此先哲们基于一系列假设把现实世界简化到从概率上来说正确,从复杂程度上来说可认知的程度,就得到了知识(理论)。正因为简化,所以知识是不完全的,即使对同样一个事件,由于观察角度不同,简化标准不一,都可以得到不同的理论,但是这些理论都是“对”的,但也是不全面的;只有“观察——简化——推理——判断”的“活”的思维习惯才能帮助人相对正确的简化现实世界,超越表象,在理论上做出创新,在实践中高瞻远瞩。(把握好不确定性,使得理想与现实的矛盾得以调和)
————有时候,我们去解读一个人或者一件事情时,往往也是片面的去下定论,殊不知,或许我们看到只是片面,只是表象。有时候,选择沉默,选择用心去深入看,可能是最明智的做法。
在学校里,“横扫图书馆”的生活并不属于我,因为这既不可能,也不可以。虽然每个领域都如此的吸引人去思考,每一套理论体系都能解释很多的现象,但是没有一个理论能解释和语言所有的现象,没有一个理论能消除未来的不确定性。
很诧异这世界上优秀的人怎么会用同样的时间融合那么多的知识?
其实,他们不是看了那么多文献才提出自己的见解的,对每一个现象都是先自己观察,自己思考,理清其中的逻辑脉络,形成自己的观点再去看别人的文献,这样你可以知道每个人的贡献在何处,缺陷在何处,你会发现事实上很多文章是不值得看的,活的思维远比死的理论重要。(放弃“博而不专”的习惯吧,不要以“真实有用”作为评价理论的标准,注重培养自己的思维,分析理论观察什么,简化了什么,如何推理。要求自己去思考而不是记忆)
教育的目的不是学习知识,也没有任何知识可以在复杂多变的真实世界中给出确定的答案,可以让人不加思考的执行就获得幸福。教育的目的只在于培养人面对不确定性的能力,使人形成自己习惯的思维方式,懂得如何去观察这个世界复杂的现象,对其进行简化,提取重要的信息分析、综合,然后做出推理、判断,最后依据事实反思、修正自己思维的过程。
现实不但要求我们简化纷繁额表象,也要求我们把那些理论简化了的东西还原回去。
虽然思维比理论更加重要,但这并不意味着我们可以不学习理论而自由的放纵思想;恰恰相反,要获得思维,理论是最好的训练。(研究生阶段学习应该分为三个阶段:掌握基本工具,掌握思维方式并熟悉一个领域,用规范的方法表达新的观点)
————我们在学习知识时,不要只想着去接收,而是要站在他人的肩膀上,对理论有所贡献。就如读论文,我们想到的不应该知识吸收、赞同是它所表达的内容,而是在把握整体框架的基础上,思考为什么作者会这样做,这样去解决问题,得到的结果又是什么?当然最后更重要的也是思考作者在解决问题上还有没有缺陷。
“理论只是一张地图而不是现实的路径”。我们不用在“真实性”上做任何纠缠,我们也不需要精确的描绘每一方面而只需要抽象出轮廓,这在这个复杂的世界中已经足够了。所谓的简化,是指用尽可能少的变量解释尽可能多的现象,不但在空间上稳定,而且要在时间上能够承受历史的考验,这样才能最大限度的节约信息。理论的正确性不在于能 $100\%$ 预测未来。
理论绝不是枯燥的,高深的数学相对于现实是一种简化,一部部巨著,一首首诗篇、一部部电影、一幕幕舞蹈、一曲曲音乐相对于这个世界如何不是一种简化?
————停下匆忙的脚步吧,给大脑一点自由发挥的空间,其实眼前的万物都可以被思维,被简化,被抽象。
对问题进行分析和评论,写作能强迫你认真的分析,加深对现实的理解。
老人摔倒,扶,还是不扶?
最近几年经常看到“老人摔倒,该不该扶?”一类的报道及大家对此展开的讨论,其中说法各异,虽然不少言辞渗透出负面的信息,但由此类展开的关于社会、法律和道德等方面的讨论却引起了我的深思。
从2006年的“彭宇案”,到前不久四川达州声称被三个小孩推倒的老太太蒋某系自己摔倒案件,这期间类似的事件发生了多起。看到一位老人跌倒在身边,你扶,还是不扶?如今这个问题让很多人都陷入了纠结,伴随着恩将仇报的见义勇为、惹祸上身的助人为乐使得传统美德陷入了一种莫名的尴尬。特别是“彭宇案”、“许云鹤案”的判决结果,让很多公众在此事上都表现出负面的情绪。
但我们有没有深入思考过这类案件产生的原因,或者将视角深入到更高层面去看待这类问题?
是老人坏了,还是坏人老了?
随着近些年经济发展步伐的加快,很多社会问题都浮出水面,人口红利带来的经济发展模式受到挑战,社会的老年化问题越来越严重,一方面社会养老压力加大,特别是城乡老人收入水平较低,增长慢,另一方面老人服务和养老方式不够完善,医疗保险覆盖率低,农村缺医少药。在这样的大背景下,陆续出现了“彭宇案”,看到一个老人跌倒,从道德上讲,我们应该路见不平施以援手,但是当你伸出手时,不该有的事情发生了,所有的事情都要你一个人扛,这样的情况下,救助者都会左右为难,无从下手。
当今社会,是老人坏了,还是坏人老了?
针对此事件,我们从结果分析其本质。老人指助人者为肇事者,或者没事而谎称有事,最后无不是因为找不到真正的肇事者而需要担负医药费,或趁机讹诈一笔改善生活等。老人们这些纯粹的目的,无疑应引起我们深刻的思考。如果老人们生活在一个社会保障系统健全的社会,其权益、生活、医疗等都有真正落实到位的保障,这类的时间还会发生么?
再从案件结果出发,如果一个社会有完善的法律程序、道德指南,就不会出现“彭宇案”等让人面对老人摔倒事件望而却步的判决结果。没有撞人并做了好事却要上法庭,且没有证人的情况下被判定为要付法律责任,又怎么不让人产生负面的情绪,唤起人们以后从道德角度进行施救呢?
在围观中思考如何搀扶正义
老人跌倒,我们理应该出手时就出手,而不应该采取事不关己,高高挂起态度。继这类事情发生之后,我们该如何在围观中搀扶正义?
政府相关部门应该颁发更健全的社会保障体系,特别是针对当前老年化问题日益突出的社会,除了保障体系,更重要的是将具体政策落实到位,在落实过程中可以采取监管等措施。
国家应该修订相关法律,让摔倒事件得到公平公正的处理,不能因为是老人就享有做错事情而不受惩罚的权利,也不能因为片面之词就错判好人。相关公益网站对此类事件产生的官司,可以提供免费的法律援助等。
人之初,性本善,我们应该要坚信人性之美,传承中国的传统美德,不能因为个别事件而“废食”。在具体实施帮助的时候,可以先分析情况,如果老人意识清楚,就问询老人跌倒情况及对跌倒过程的记忆,如果不能记忆,可以记录自己的帮助过程、打电话急救等等。
结语
老人跌倒,扶还是不扶的纠结,归根结底是社会保障的不健全、法律的缺失及道德的退步。我们要解决这类问题,必须从健全并落实完备的社会保障系统、修补法律漏洞和大力弘扬传统美德等方面出发,才能从根本上解决这些问题,才能在社会上唤起人间的正义、社会的公平,让整个社会呈现出一片和谐和关爱。
由一段代码引发的思考
因为一个馒头可以引发血案,同理,由于一段小小的代码,亦可引发一番深刻的思考。代码如下图所示:
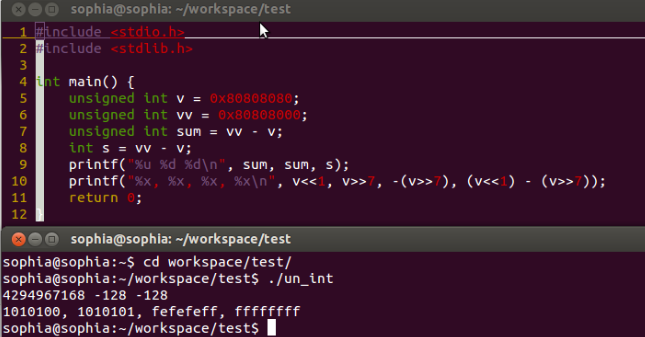
图中上一个窗口为代码,下面窗口为其对应的输出。如果我们撇开各种变量的类型,其实在计算机中数值存在的状态就是 0 和 1,没有特殊的意义和体征,就如上面所述的两个无符号的 int 型变量相减,在计算机中运算时仍然满足先求补码然后再异或运算,最后的结果在计算机中仍就只是一串 01 字符,对这串字符我们可以说是无符号的 int 型?是负数?还是其他?
其实我们设定的输出格式,就是为某一串 01 字符定义了体征,所以会有图中相应的输出。
机器中的 01 字符本没有体征,只是我们人为去定义了,所以才有了所谓的 int,无符号 int 等等。同理,在整个浩瀚的宇宙,任何事物都是没有体征的,都是我们在自己的角度,用自己的心去定义了,所以才有了形形色色、不同特征的万物。例如当你看到一棵树,它真的是树么?只是我们将其称为树,在自己的脑海里潜移默化的定格下这样的概念:有叶子、有枝干、有根的物体就是树,所以当我们每次看到时就会无条件反射:那是一棵树。
在这个物欲横流的世界,我们有太多的在乎,有太多的盲目,有太多的无知,所以每时每刻,我们都在忙碌,都在焦虑,纠结,痛苦……但是我们真正停下来,去透过那层笼罩着我们心的那层薄雾,去看清事物真正的本质,我们的盲目、无知、在乎,其实全都是一个天大的笑话。
有些东西,不是不重要,只是你的在乎表现过度了,所以你会觉得痛苦,会觉得这些东西距离自己越来越遥远。看清事物那本来无有体征的体征吧,不要盲目的用自己的心给万物着上颜色,那时,你会猛然发现,就算太阳不再升起,就算寒风刺骨袭来,你亦可淡然而笑之。
doxygen系列问题
Doxygen是一个比较强大的、针对源代码的开源文档生成系统,其适用的语言有C++、C、Java、Objective-C、Pyhon、IDL、Fortan、VHDL、PHP、C#以及D语言。现有很多开源项目都使用到了doxygen。它的出现使得文档的维护工作大大简化,只需要根据一定的规则的注释,就可以生成质量比较搞的文档。现在的doygen能支持一般的操作系统,如windows、unix、Mac等等。
下面对doxygen作进一步的分析:
一、安装
由于我使用的是linux系统,所以,整个文章的内容都是关于doxygen在linxu下的使用;在linux下,doxygen的安装如下:
sudo apt-get install doxygen
真正在使用上windows下的doxygen还是比较直观的,应该更适合一些人群,因为有GUI界面供使用,网上的教程也很多。
二、基本使用:
1. 生成配置文件:(filename是相应的配置文件名,如果缺省,默认是Doxyfile):
doxygen -g filename
2.修改配置文件:
这里说一些我认为比较重要的几处,其他的可以根据相应的选择进行设置(其实在配置文档的注释中,各项已经非常明朗了)。
| PROJECT_NAME | 写入你的项目名称,在生成的时候会涉及到 | 默认为"my project" |
| PROJECT_NUMBER | 指的是你工程的版本号 | 可以选择不写 |
| OUTPUT_DIRECTORY | 最后输出的目录选择,例如"./doc/" | 如果不写,默认是当前目录 |
| JAVADOC_AUTOBRIEF | 修改成YES,表示支持java的注释格式 | 默认是NO,在代码中,总要设置几个注释规范 |
| MULTILINE_CPP_IS_BRIEF | 和上面一样,改成YES | 默认是NO,目的和上面一样 |
| INPUT | 源project的目录或者文件名,例如"./lib/" | 可以不写,表示当前的目录 |
| FILE_PATTERNS | 选择如.c/.h/.cpp等的文件 | 没有被选择的,如.py会被过滤掉,即最后不会翻译.py的文件 |
| RECURSIVE | 递归遍历当前目录的子目录,寻找被文档化的程序源文件 | 默认是 NO,修改成 YES |
| HAVE_DOT | 改写成YES | 生成类图等,前提是需要安装了这个组件 |
其他的,个人觉得不太重要,至于其他的可以参看注释,生成文件的每项注释已经非常清楚了。
3. 写注释
这一块不想说太多了,因为已经有很多人都做了讨论,对自己选好的几种注释方式,进行研究一下即可。(可以参考http://www.cnblogs.com/wishma/archive/2008/07/24/1250339.html)
需要说明一点的是,我们在写注释的时候,也要注意使用关键字,我目前为止使用到了@file (为整个文件生成对应的页面,如 .h 文件,则可以生成与 .h 文件对应包含所有函数的整体性文件)、@fn (声明函数,可以还有 @par, @return等等其他描述函数的参数)、@brief (简要描述)等等。在生成的时候注释中的换行往往会被忽略掉,可以使用\n来产生空行。
4. 运行:
doxygen filename(配置文件名)
三、链接网站:
- doxygen的官方网站:http://www.doxygen.nl/index.html
- doxygen手册的翻译网站:http://cpp.ezbty.org/book
现在国内doxygen的使用应该是呈现了逐渐增多的态势,所以关于doxygen方面的博客等有很多很多,虽然大致相同,但是总会有些亮点。具体可以google一下。下面是我现在在学习中的一些问题和心得:
doxygen -g filename
上面是doxygen初始配置文件的生成命令,其实你可以试一下,无论你在哪个目录下,或者以哪个文件名命名这个初始的配置文件,最后得到的文件内容都是一样的,不会因为你放在哪个目录下或文件名不同而内容有所不同。这也就说明了一个问题,在使用doxygen时,对配置文件所处的位置是没有限制的,而关键的问题是对配置文件进行的修改以及设置(input和output path可以对目标文件以及输出的目录进行设置)。
如果在上面命令中缺省filename,最后得到的默认文件Docxyfile,其内容和其他生成的文件内容也是一样的。
在使用的过程中,因为我的粗心,也出现了一个问题。这里指出来,提醒我自己。
配置文件中有“INPUT PATTERNS =”这个设置项,主要作用是如果你之前INPUT了一个目录而不是一个文件的情况下,过滤性的对源码生成文档。例如:
INPUT PATTERNS = *.cc *.h *.cpp
上面表示的就是只针对目录下所有的.cc、.h和.cpp源文件生成文档,其他后缀的文件都会被忽略,而我最开始接触这个东西的时候,在网上搜到的大部分设置都是这样的:
INPUT PATTERNS = *.cc \
*.h \
*.cpp
我知道“\”是一个换行符号,但是我在使用的时候没有注意到“*.cc”和其之间要有空格,所以这样一来始终都生成不了对应的文档。问题的本质应该在于,doxygen在运行的时候,是根据空格来区分多个参数的,如果不加空格,可能直接被识为了后缀为.cc*.h*.cpp的文件,而目录下是没有这样的文件的,所以会出错。
Makefile Introduce
这两天一直在一个大型的分布式存储系统上做工作,今天应该算是初步完工了,提升了初步的编程技能外,一个意外的收获就是对makefile的了解和初步掌握。在这之前,我只写过一个小型的makefile文件,当时是按照网上的资源仿写的,没多太在意,但是通过这次的工作,makefile的重量才在我心里固定下来。
学长给我的学习资料“和我一起写Makefile”(author:陈浩),感觉很不错!接下来,我也要小小的总结下makefile究竟是怎么回事,不涉及具体的写法。
很多Windows程序员都不知道makefile这个东西,因为windows的IDE为你做了这个工作,但是作为一个professional的程序员,这个还是要懂的。“会不会写makefile文件,从一个侧面说明了一个人是否具备完成大型工程的能力。”
我们常常在unix或者linux用到的make其实是一个命令工具,是解释makefile中指令的命令工具,很多IDE都有这个命令。虽然说不同的的环境下,make各不同,但是究其核心,都是“文件依赖”。虽然学过编程语言的人都知道编译和链接,有多少人能很清楚的说明白这个东西呢?
不管怎样,我们先来复习下这个概念。写了一个源文件,首先是将其编译成中间代码文件,在windows下是.obj,在unix下是.o,都是所说的object file;然后将大量的object file合成可执行文件。前者主要是在语法的正确性/函数与变量声明的正确性上做文章;而后者主要是基于object file,链接函数和全局变量,如果找不到函数的实现,就会报错。
类似于很多语言,如latex,python,c,c++等,都有自己一个固定的书写格式,makefile也是这样的,我们可以将makefile作为一种脚本语言。基本的三要素:target(目标文件),prerequisites(依赖项),command(命令)。target可以是一个或多个,依赖于prerequisites,而执行的定义则是在command里的。
最后,要说明一下,make是如何工作的:
1. make会在当前目录下找名字为“Makefile” or “makefile”的文件;
2. 如果找到,它会在文件中的第一个目标文件(target),把其作为最终的目标文件;
3. 如果第一个目标文件不存在或者是其后面依赖项修改了,就会执行command重新生成最终目标文件;(通过更新时间来判断是否是最新的)
4. 如果第一目标文件后的某依赖.o不存在,make会在当前文件中找到该依赖.o,然后利用相应规则生成该.o文件;
5. .o文件后面的依赖项目会是源文件,所以c文件和h文件是不可缺少的。
要注意,make只管文件的依赖项,如果找不到或缺失,是会报错的。
下面是我的一个makefile文件:
AR = ar #ar是默认的函数打包程序;可以声明命令的变量! CC = g++ #命令的变量,编译c++命令 CFLAGS = -g -Wall -fPIC #这是g++的命令参数,-g指的是在编译的时候给出调试信息;-wall生成所有警告信息; OUTPUT := ./encoder ./decoder ./repair INCS_HEAD := ./nlib ./nlib/codes ../../common ../../nandora ../../message ../../client/src ../../ns/src ../../ns/src/btr LIB_PATH := -L ../../lib LIBS := -lclient -lcommon -lmessage -lnandora -lthread -lrt SOURCE := $(wildcard *.cpp) #wildcard意思是所有SOURCE是所有。cpp文件的一个集合 OBJS := $(patsubst %.cpp, %.o, $(SOURCE)) #原型是$(patsubst <pattern>, <replacement>, <text>)模式字符串替换函数, #NOBJS := ./nlib/*.o ./nlib/codes/rc.o NSOURCE := $(wildcard ./nlib/*.cc) ./nlib/codes/rc.cc #定义变量的时候,特别是多个一起并列,中间不用逗号; NOBJS := $(patsubst %.cc, %.o, $(NSOURCE)) LIBOBJS := $(filter-out encoder.o decoder.o repair.o, $(NOBJS) $(OBJS)) #前者过滤掉,防止多个main函数报错,后者是要包含的 ENCODEROBJS := $(filter-out repair.o decoder.o, $(NOBJS) $(OBJS)) DECODEROBJS := $(filter-out encoder.o repair.o, $(NOBJS) $(OBJS)) REPAIROBJS := $(filter-out encoder.o decoder.o, $(NOBJS) $(OBJS)) #:来源,以及操作,注意命令操作时最开始必须有一个tab健;addprefix给每个单词加前缀,-I**; %.o:%.cpp $(CC) $(CFLAGS) $(addprefix -I,$(INCS_HEAD)) -c $< -o $@ all:$(OUTPUT) ./encoder : $(FRCENCODEROBJS) $(CC) $(CFLAGS) $(addprefix -I,$(INCS_HEAD)) $(LIB_PATH) -o $@ $^ $(LIBS) ./decoder : $(FRCDECODEROBJS) $(CC) $(CFLAGS) $(addprefix -I,$(INCS_HEAD)) $(LIB_PATH) -o $@ $^ $(LIBS) ./repair : $(FRCREPAIROBJS) $(CC) $(CFLAGS) $(addprefix -I,$(INCS_HEAD)) $(LIB_PATH) -o $@ $^ $(LIBS) clean: -rm -f $(OBJS) -rm -f $(NOBJS) -rm -f ./nlib/codes/rc.o -rm -f $(OUTPUT)
每种语言都有其固定的一个格式,万变不离其宗。makefile 文件在书写的时候,编译方式、编译格式、输出的目标文件、依赖关系、clean 内容等等,这些一般都是会被包含的内容。每次理解一个makefile文件时,按照这些内容对号入座,问题就变得相对简单了。作为一个初学者,我觉得对文件中相应代码做注释来理解是一个比较好的学习方法。
文件指针 PK 文件描述符
最近在边看边写一个分布式文件系统的东西。其实对于基本的思路是很明确了,但是单单就在一个文件系统的操作上就耗费了有两个多小时,而且晕了。后来,为了彻底弄清楚,我查阅了很多资料,在这里归纳一下,算是对自己以后的提醒把~!
我们经常看到fopen()或者open()函数,但是具体针对什么情况下使用?这两者的区别又是什么?我们的了解又是多少呢?
解决这个问题之前,我们先说说文件描述符和文件指针的概念。
//FILE的结构
struct_iobuf {
char *_ptr; //缓冲区当前指针
int _cnt;
char *_base; //缓冲区基址
int _flag; //文件读写模式
int _file; //文件描述符
int _charbuf; //缓冲区剩余自己个数
int _bufsize; //缓冲区大小
char *_tmpfname;
};
typedef struct_iobuf FILE;
我们通过上面FILE的结构,可以看到文件描述符是定义在其中的。文件描述符相当于一个逻辑句柄,而open,close等函数是将文件或者物理设备与句柄相联的。在linux中,通常把设备和普通文件都看作是文件,要对文件进行操作就必须先打开文件,打开文件后会得到一个文件描述符,它是一个很小的正整数(声明时是int fid),也是一个索引值;内核会为每一个运行中的进程在进程控制块PCB中维护一个打开的记录表,每一个表项都有一个指针指向打开的文件,上边的索引值是记录表的索引值。如下图示:
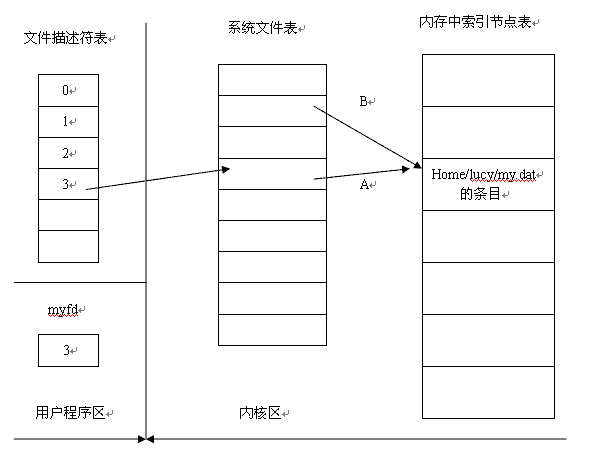
文件描述符兼容POSIX标准,很多系统调用都可以依赖于它,但是缺点也很明显,它不能移植到unix之外的系统上去。
而文件指针是ISO C的标准I/O库中的,类似于unix中使用文件描述符作为文件句柄,C语言使用文件指针(FILE *fp)来作为操作文件的I/O句柄,且文件指针指向的是进程用户空间的一个FILE结构的数据结构(主要包含一个I/O缓冲区和一个文件描述符),所以在某种意义上而言,文件指针就是句柄中的句柄(在windows文件描述符被成为文件句柄)。文件指针的优点是便于移植,且是C语言中的通用格式。
文件描述符是唯一的,但是文件指针却不是唯一的,而其指向的对象是唯一的。既然文件指向一个FILE结构,而FILE结构里又包含有文件描述符,所以在C语言中,文件指针和文件描述符之间是可以相互转换的:
int fileno(FILE * stream) FILE * fdopen(int fd, const char * mode)
总结一下,C语言中使用文件指针对文件操作,对应的库函数分别是fopen(), fclose(), fread(), fwrite(), fscanf(), fprintf()等等,且文件指针有很好的可移植性。而文件描述符是unix系统对文件操作的入口,不具备良好的移植性,对应的I/O函数是open(), close(), read(), write(), ioctl()等。下面是以fopen()和open()函数为例给出的具体区别:
| open() | fopen() |
| 返回文件描述符 | 返回文件指针 |
| 无缓冲 | 有缓冲 |
| 与read()和write()配合使用 | 与fread()和fwrite配合使用 |
我也在网上搜索了一下python的文件操作,比较类似于unix系统,而且在代码的阅读上比较直观,具体可以看一下:
http://www.cnblogs.com/rollenholt/archive/2012/04/23/2466179.html
参考文章链接:
http://www.cnblogs.com/qianye/archive/2012/11/24/2786357.html
http://www.cnblogs.com/hnrainll/archive/2011/08/16/2141354.html
ping && url/uri/urn
这个标题很多人初次一瞥,可能会觉得没有什么可以说的。的确,这个问题是一个简单的问题,但是正是因为太简单了,所以,在编写程序时,往往不会注意到,我也其中一个,所以在此做点总结,用来警醒自己,也希望这篇文章能对初学者有些许帮助。
通过维基百科,可以看到这样的定义“ping是:一个电脑网络工具,用来测试待定主机是否通过IP到达”,具体的工作原理是利用网络上机器IP地址的唯一性,给目标地址发送一个数据包,再要求对方发送同样大小的数据包来确定两台机器是否连通,时延是多少。
其基本格式是ping [某个主机IP],根据结果的不同情况来判断网络情况以及故障原因。这里外加提一点,ping to death,其实是一些木马等病毒程序会不断给某服务器发送ping,抢占服务器资源,导致不能正常应答其他请求,最后整个系统崩溃不能工作。
所以,在使用ping时,要注意,你ping的对象是否是一个IP地址,还是简单的url网络资源,例如:
ping http://music.baidu.com ping http://music.baidu.com/top/dayhot
第一个ping使用是可以ping通的,而后者是ping不通的,原因很简单,因为前者的地址对应的是一个服务器的IP地址,而后者对应的是一个url网络资源,不符合ping的基本“范式”。(我这几天因为这个东西犯错了,总结还是对url和ping的概念以及知识的掌握不够深入)
除了上面的简单总结,我还想回顾一下uri,url和urn,加深印象。
- URI:uniform resource identifier,统一资源标识符;
- URL:uniform resource locator,统一资源定位符;
- URN:uniform resource name,统一资源名称;
其中,uri和urn是uri的子集,网络上每个资源,如html文档,图像,视频,表格,文字等,都是通过uri来进行定位的。这三者基本都是由三部分构成:协议/主机IP(端口)/主机资源目录(一般以目录形式存在)。可以这样来比喻,一个网站就是一个大屋子,uri就是这个屋子的大门,而url就是对屋子里的每个物品进行了标识,urn就是这些物品能被计算机理解的名字。
PS:这里我可能说的不是很充分,但是,我觉得只要记住这些就已经差不多了,主体就已经出来了。
以太网&&10M家庭宽带
“以太网是什么?”
这是很久之前,有人问我的一个问题,当时,我就呆了,我好像从来没有考虑过这个问题,我只知道以太网是一个局域网的协议,至于现在每个人都知道的以太网和这里的协议是不是一回事???
到现在为止,我也不是太清楚。又认真翻看了一下课本,我推测可能是这样的。由于以太网是目前为止最流行的有线局域网技术,而且几乎完全占领着现有的市场,以太网硬件(适配器以及交换机)成了一个很普通的商品,所以现在人们口中的以太网应该是使用了以太网技术的网络。
不知道这里的分析是否正确??
很多时候家人总是抱怨在某个时段,家里的10M宽带很慢,而我的解释总是说“这10M是共享的,而不是专有的,运营商是根据一个概率来计算,保证没人使用的时候是10M!”因为之前的网络课,提到过,但是现在记忆中只有简单的答案,而我今天又翻了翻网络书,得到了算是一个比较满意的答案。
其实网络是可以分为电路交换网络和分组交换网络,前者因为对网络资源的浪费现在已经很少用到了,只是一些大型的,需要网络带宽保障的公司现在还在使用,但是这类网络一般都很贵。我们现在家庭装的网络基本都是后者。
电路交换链路中通过频分复用和时分复用(前者一个将频率分成一片一片,每个人享有固定的频率区间;后者是将时间分成一片一片,每个人也有固定的时间使用整个网络),但是,人们不可能每时每刻都在网络上传输数据,这样以来,就会造成很多浪费。所以后来出现了分组交换网络(核心:存储转发,分组交换),其端到端的时延是不可预计的,但是它较分组交换网络有两点优点:提供了更好的带宽共享;更简单,有效,且实现成本更低。
假设有1Mbps的链路,电路交换有10个用户,可以每个用户有完整的100kbps恒定速率。而对分组交换,一个特定用户活动的概率是0.1,如果有35个用户,有11或更多同时上网活动的用户概率大约是0.0004,也就是a(a<=10)个用户在网上活动的概率为0.9996,这样一来,每个人享有的带宽是1Mbps/a >= 100kbps。
这个例子说明了在同一带宽的情况下,分组交换网络能够维持更多用户,所以,在某个特定的时刻,上网人数猛增的话,会导致人均占有的网络带宽明显下降。(而且有排队时延)
PS:在一个小区内,运营商基本只会设置一条固定带宽的链路。